

A rocket company offered $60 billion for a coding text editor.
SpaceX just announced that it had struck a deal with Cursor giving it the right to acquire the San Francisco coding startup outright later this year for sixty billion dollars, or to pay ten billion for the ongoing work the two companies are doing together. Two weeks earlier, OpenAI confirmed that Codex had crossed 4 million weekly developers, up from 3 million in the prior fortnight. In the same window, Anthropic reported that revenue from its Claude Code product had surged. Google (NASDAQ: GOOGL) ships Antigravity, launched last November alongside Gemini 3, an agent-first development platform that treats the AI as the primary actor.
Four frontier labs. Four coding products. One battlefield.
The AI wars are now coding wars, and the winner is whichever lab ships the best coding tool. Not the best chatbot. Not the best search. Not the best voice assistant. The best coding tool. The winner owns the operating system of the agent economy, because code is the substrate every other agent runs on.
Why xAI Had To Buy Cursor
Three companies train frontier-scale models that lead on published benchmarks: Anthropic, OpenAI, and Google DeepMind. Each ships a first-party coding product (Claude Code, Codex, Antigravity) built on its own models.
xAI , the AI lab Elon Musk founded, is not on that list. Musk said at a conference that Grok "is currently behind in coding." His original eleven xAI cofounders have all left the company. After SpaceX acquired xAI in February at a combined $1.25 trillion valuation, Musk wrote publicly that xAI had not been built right the first time and needed to be rebuilt from its foundations.
The rebuild was a buy. In March, xAI hired Andrew Milich and Jason Ginsberg, two former Cursor product engineering leaders, who report directly to Musk and to xAI president Michael Nicolls. On April 21 the Cursor deal followed. Cursor had crossed $1 billion in annual recurring revenue in November 2025, was used by more than half of the Fortune 500 including Uber (NYSE: UBER) and Adobe (NASDAQ: ADBE), and counted both Google and NVIDIA (NASDAQ: NVDA) as investors. Nvidia CEO Jensen Huang told CNBC in October that "every one of our engineers, 100 percent, is now assisted by AI coders," naming Cursor specifically as his favorite enterprise AI service. Cursor's own blog acknowledged that compute had been the constraint on further model training and said access to SpaceX's Colossus supercomputer, which SpaceX describes as equivalent to roughly one million Nvidia H100 chips, would scale up the intelligence of its models.
The truth is three frontier labs trained their way in, and now one compute-and-distribution bet is buying its way in. SpaceX was not acquiring optionality. It was acquiring a coding tool, because coding is the prize, and the lab it already owned was too far behind.
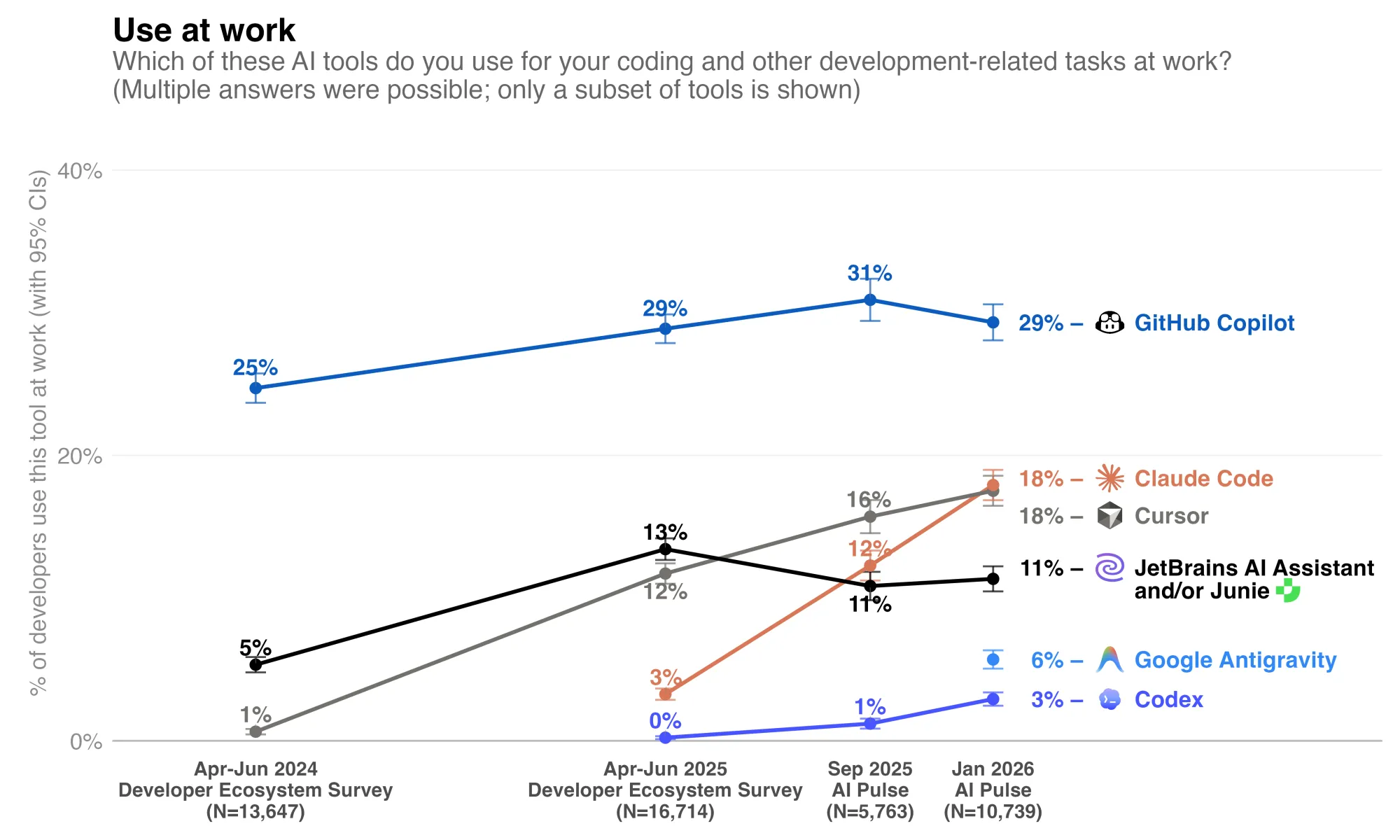
The numbers are now measured, not assumed. JetBrains' January 2026 AI Pulse survey of more than 10,000 professional developers worldwide found that 90% regularly use at least one AI tool at work, and 74% specifically use specialized AI developer tools beyond generic chatbots. GitHub Copilot (NASDAQ: MSFT) remains the most widely adopted at 29%, but its growth has stalled. Cursor and Claude Code are now tied at 18% global adoption, with Claude Code having grown 6x between April 2025 and January 2026 and reaching 24% in the US and Canada. Claude Code posts a CSAT of 91% and an NPS of 54, loyalty metrics that almost no enterprise software product achieves. JetBrains' research head framed the market pattern bluntly: best-of-breed standalone agents are winning over ecosystem lock-in, and integrated stacks that bundle adequate AI get replaced by standalone tools that are actually the best.
Why Coding Is The Prize
Every platform shift has a control point. In the PC era, it was the operating system. On the web, it was search and distribution. In mobile, it was the app store. In AI, the control point is increasingly clear: code.
Coding is not just another knowledge-work category waiting to be automated. It is the mechanism by which automation itself is built. The company that wins coding does not merely help engineers move faster; it gains leverage over the creation, deployment, and improvement of every downstream AI agent. That is why the fight over AI coding tools is not a side market. It is the main event.
The reason is simple. Code has three qualities that make it uniquely valuable: it produces other tools, it generates unusually clean feedback, and it sits inside the highest-value labor pool in the enterprise. As frontier models improve, the prize is no longer autocomplete or pair programming. The prize is control over the software factory itself.
Coding is the master skill. When an AI can write, test, debug, and deploy software, it does not just automate one task. It automates the production of the tools that automate every other task. The customer-service agent, the legal-review agent, the supply-chain monitoring agent, all of them are built, deployed, and modified by engineers using coding tools. Control the coding layer and you influence every agent downstream.
The training signal is verifiable. Code compiles or it does not. Tests pass or they do not. Production breaks or it does not. No other domain offers training data this clean. Models that code better get measurably better; models that write prose require human judges who disagree.
The willingness to pay is the highest in the enterprise. Engineering organizations burn tens of billions of dollars a year on developer salaries and tools. Every productivity point is real money. That is why OpenAI is willing to share distribution with the Big Seven consultancies (Accenture, Capgemini, CGI, Cognizant, Infosys, PwC, and Tata Consultancy Services) under its Codex Labs program. That is why SpaceX is willing to pay sixty billion dollars for an editor.
Capability is converging at the frontier. On SWE-bench Verified, the benchmark that measures whether a model can resolve real GitHub pull requests, Claude Opus 4.7 scored 87.6% in April 2026, up from 80.9% on Opus 4.5 in November 2025. GPT-5.3-Codex reached 85.0%. Gemini 3.1 Pro reached 80.6%. Three years ago, these scores would have seemed impossible. Today, they are roughly a quarter apart.

METR, an independent AI evaluation lab, publishes a live dashboard at metr.org/time-horizons that tracks the longest software engineering task a frontier model can complete autonomously with 50% reliability. In 2019 the answer was 30 seconds. In early 2024 it was 30 minutes. By early 2026 leading models had crossed one hour and were moving toward two. The doubling time has run between four and seven months for six consecutive years, with signs the curve is accelerating. Extrapolate honestly and within 24 months coding agents reach the time horizon of a full work day. When that happens, the bottleneck moves.
The Marginal Cost Of Software Is Going To Zero
When coding agents can complete day-length tasks, the marginal cost of producing software collapses toward the cost of inference tokens. That collapse is not speculative. Two public datasets show it is well underway.
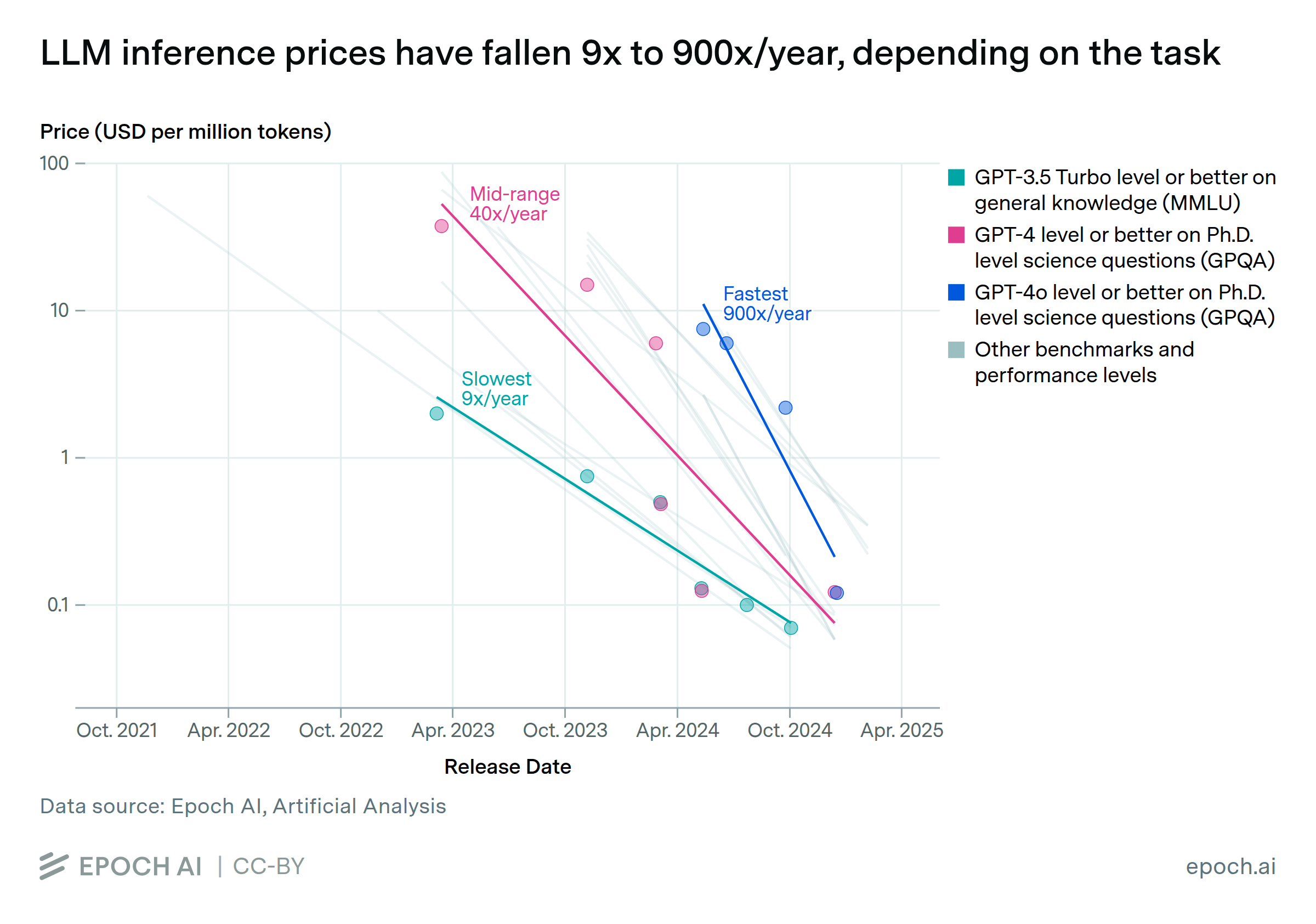
Price-for-capability is falling up to 900x per year. Epoch AI analyzed inference prices across six major benchmarks and found that the cost to achieve a given level of benchmark performance has fallen between 9x and 900x per year, depending on the benchmark, with the fastest declines in the past twelve months.
Algorithmic efficiency alone is improving roughly 3x per year. A separate Epoch analysis isolates algorithmic gains from hardware gains. Pre-training compute efficiency is doubling every 7.6 months. Hardware price-performance is improving an additional 37% per year.
Concrete illustration. On the FrontierMath benchmark, reaching 27% accuracy required about 43 million output tokens using OpenAI's o4-mini with high reasoning effort in April 2025. By December 2025 the same result took roughly 5 million tokens on GPT-5.2 with low reasoning effort. An order-of-magnitude cost compression in eight months, on a single benchmark.
Software has always been expensive to produce. Expensive production implies a narrow product taxonomy: generic tools, standardized, sold to many to amortize the cost of serving the few. That is the entire SaaS era. Collapse the production cost and the taxonomy changes. Three categories become economically viable that were not before:
Personalized software. An application built for one employee's workflow, one department's exception case, one customer segment's requirement. Not configured. Authored.
Custom software on commission. A mid-market company commissions the specific CRM it actually wants, rather than contorting Salesforce (NYSE: CRM) to fit. The commission costs days, not quarters.
Disposable software. An application built for a single campaign, a single merger integration, a single regulatory deadline, then deleted.
The competitive moat shifts. Advantage no longer rests on owning software competitors lack. It rests on owning data competitors cannot reach, distribution competitors cannot buy, and governance competitors cannot match.
Why Coding Tools Beat Web Chat
A director using ChatGPT or Claude through a browser tab has seen a fraction of what these systems can do. The web interface reads one message at a time, carries no persistent context on the codebase, cannot run commands, cannot test its own work, and cannot commit changes to production.
Claude Code, Codex, Antigravity, and Cursor operate inside the physical location where software is actually built. They hold context across thousands of files. They execute commands and read the results. They spawn parallel agents in cloud sandboxes that keep working while the engineer sleeps. They commit to production.
The difference is the difference between giving someone advice and giving them the keys.
API, MCP, CLI In Plain English
Three acronyms explain how the agent economy actually works.
API (Application Programming Interface). The doorway between two pieces of software. When your bank's app shows your balance, it is calling the bank's API. APIs have existed for decades. AI has turned every API into a lever an agent can pull on its own.
MCP (Model Context Protocol). The universal adapter for AI. Before MCP, every connection between an AI system and an enterprise tool (Salesforce, Gmail, Slack, SAP, Workday) required custom engineering. MCP standardizes the conversation so any AI can talk to any tool through the same interface. Think of it as USB-C for agents. Anthropic introduced the protocol in late 2024. Every major AI lab now supports it. This is the plumbing that makes the agentic enterprise possible at scale.
CLI (Command Line Interface). The engine room. Instead of clicking buttons, the user types commands the computer executes directly. Professional developers live in the CLI because it is faster, scriptable, and automatable. When Claude Code or Codex CLI runs in your terminal, the AI is operating the machine directly.
Combine the three. Agents use the CLI to execute. MCP standardizes their connections to enterprise tools. Each tool exposes an API the agent calls. That stack is the operating system of the agent economy, and the four coding platforms are the first-generation interfaces built on top of it.

Tokenmaxxing
Silicon Valley now has a word for using as much AI as possible: tokenmaxxing.
Let's remind you what a token actually is. An AI model does not read words the way a person does. When you send a message to Claude, Gemini, GPT, or any other large language model, the system first chops your text into small pieces called tokens. A token can be a whole word, a fragment of a word, a space, a punctuation mark, or a symbol. As a working rule for English, one token is roughly four characters, or about three-quarters of a word. A paragraph of 75 words is around 100 tokens. The model also counts its own response in tokens, so every interaction has two meters running: input tokens (what you send in) and output tokens (what it sends back). Every AI vendor bills by the token. Every vendor caps how many tokens a model can consider at once, a limit called the context window. When a conversation exceeds the context window, the oldest tokens fall out of scope and the model stops remembering them.
Tokens are therefore both the unit of computation and the unit of cost. They are what your engineering and finance teams are actually buying when they buy AI. Billions of tokens per month is now a normal enterprise line item.
In April 2026, the Wall Street Journal reported that Meta Platforms (NASDAQ: META) had an internal leaderboard ranking employees by personal token consumption, with titles like "Token Legend" for top users. (The leaderboard was taken down after the story broke.) Enterprise AI company WRITER runs its own leaderboard where the March 2026 leader burned nearly 11 billion tokens in a single month, consumption that costs the company roughly $50,000 on its own platform. Sendbird runs a leaderboard. Sequoia Capital runs a leaderboard. Portfolio companies inside Sequoia run them.
Writer CEO May Habib calls internal AI adoption "existential" and defends the leaderboards even knowing employees use them to build personal side projects. HubSpot (NYSE: HUBS) CEO Yamini Rangan argues the opposite position: maximizing AI usage is pointless without measurable returns.
The debate is not the interesting part for a board. The interesting part is that this behavior is economically rational at all. Five years ago, paying employees to burn tokens for personal projects would have been irrational for any company larger than a well-funded seed startup. Today, paying for cultural velocity is cheaper than not paying for it. That is the cost curve landing on the factory floor.
And that is where the fiduciary question opens. When employees are rewarded for maximum token consumption, they point AI at problems AI should not touch, using data AI should not see, producing code that ships to systems nobody approved. The companies running these leaderboards are making a reasonable bet on cultural velocity. The boards of those companies should be asking which committee is watching what the tokens actually get spent on.
The Governance Gap
JetBrains' survey confirmed what was already obvious on the factory floor: 90% of professional developers now use AI tools at work, and 18% specifically use Claude Code, which has a product satisfaction score most incumbents have never seen. Every engineering team at every public company is in the middle of replacing its default tooling, often without the board knowing which tools are in and which are out.
Consider one governance question nobody is asking. Cursor's flagship Composer 2 model, promoted as offering "frontier-level" intelligence, was later disclosed to have been built on a Chinese open-source base model. A Cursor executive confirmed the underlying model on X, stating that license terms were being followed through inference partner arrangements. A CIO who approved Cursor deployment at a Fortune 500 company in late 2025 would have had no default way to know that detail, and no committee charter obligates its disclosure today. That is one product, one disclosure, at one of four platforms.
Consider a second question. Even the benchmark numbers deserve scrutiny. OpenAI's own 2026 audit of SWE-bench Verified found that every tested frontier model could reproduce verbatim parts of the benchmark's gold-standard answers for certain tasks, and that 59.4% of the hardest unsolved problems had flawed test cases. OpenAI has stopped reporting Verified scores and now recommends SWE-bench Pro, on which every frontier model's score drops roughly 20 percentage points. The benchmark the industry has used to sell these tools to enterprises was partially contaminated. A CIO who approved a vendor based on Verified scores had no way to know.
ISS reported in 2025 that 8% of S&P 500 boards have disclosed AI oversight. The other 92% are not auditing tools already running inside their engineering organizations. Meanwhile, Nvidia's CEO confirmed in October that 100% of his company's engineers are already working with AI coders. If deployment is universal inside the most technically sophisticated company tied to the AI buildout, the assumption that deployment at your own company remains limited and contained deserves a direct test.
That is Governance Debt in its purest form. The deployment happened. The governance did not.
A Prediction
By 2028, one of two things will be true. Either a major D&O carrier will publish formal exclusions related to losses tied to agent-authored code shipped without human review, or a public company will restate earnings due to an agent-initiated material misstatement in a reporting system. Possibly both. The coding wars are not just a product battle. They are a rehearsal for the governance of autonomous action inside the enterprise.
The Bottom Line
The AI wars are now coding wars because code is where agents prove they can act, not just talk. The lab that ships the best coding tool owns the operating system of the agent economy. SpaceX paid $60 billion for that seat at the table. Three other labs are spending more to keep theirs. JetBrains just surveyed ten thousand developers and found that the tools running inside your company are changing faster than your committee charters can track.
At your next audit committee meeting, ask five questions.
- Which coding AI tools are our engineering teams using, and which ones can commit code to production?
- What base models do those tools run on, what benchmarks was management shown at purchase, and have those benchmarks since been audited for contamination?
- Which committee approved access to corporate data by each tool, and what governs what data the model's upstream provider can see?
- Do we run an internal token leaderboard or any other incentive that rewards AI consumption volume, and who reviews how those tokens are being used?
- When an agent ships code that fails, which director is accountable?
If any answer is unclear, you have not identified five questions. You have identified your company's governance gap.
Governance Is Alpha.
Subscribe to Alpha BoardBrief at https://boardbrief.alpha.ac/




