

OpenAi just announced three new frontier models. Unfortunately, none of them are for you to use.
That is not a coincidence. It is a signal.
On the OpenAI side, the new GPT‑5.6 family comes in three tiers: GPT‑5.6 Sol, the frontier flagship; GPT‑5.6 Terra, a balanced model for efficient everyday work; and GPT‑5.6 Luna, a fast and affordable model for high‑volume tasks. All three are launching in a limited preview, restricted to a small group of vetted partners whose access has been coordinated with the U.S. government ahead of a forthcoming cyber executive order.
In parallel, Anthropic’s frontier models - Claude Fable 5 and Claude Mythos 5 - collided with U.S. export controls almost immediately, leading to Fable being pulled offline for non‑U.S. users after concerns about distillation attacks and capability leakage to Chinese firms.
These are no longer normal product launches. They are controlled deployments at the edge of capability.
The instinct is to call this regulatory capture: a handful of labs and their closest partners gaining early access to frontier intelligence, while everyone else is held back. There is real asymmetry here. But the deeper story is about what these models can now do.
The benchmark picture makes that clear.
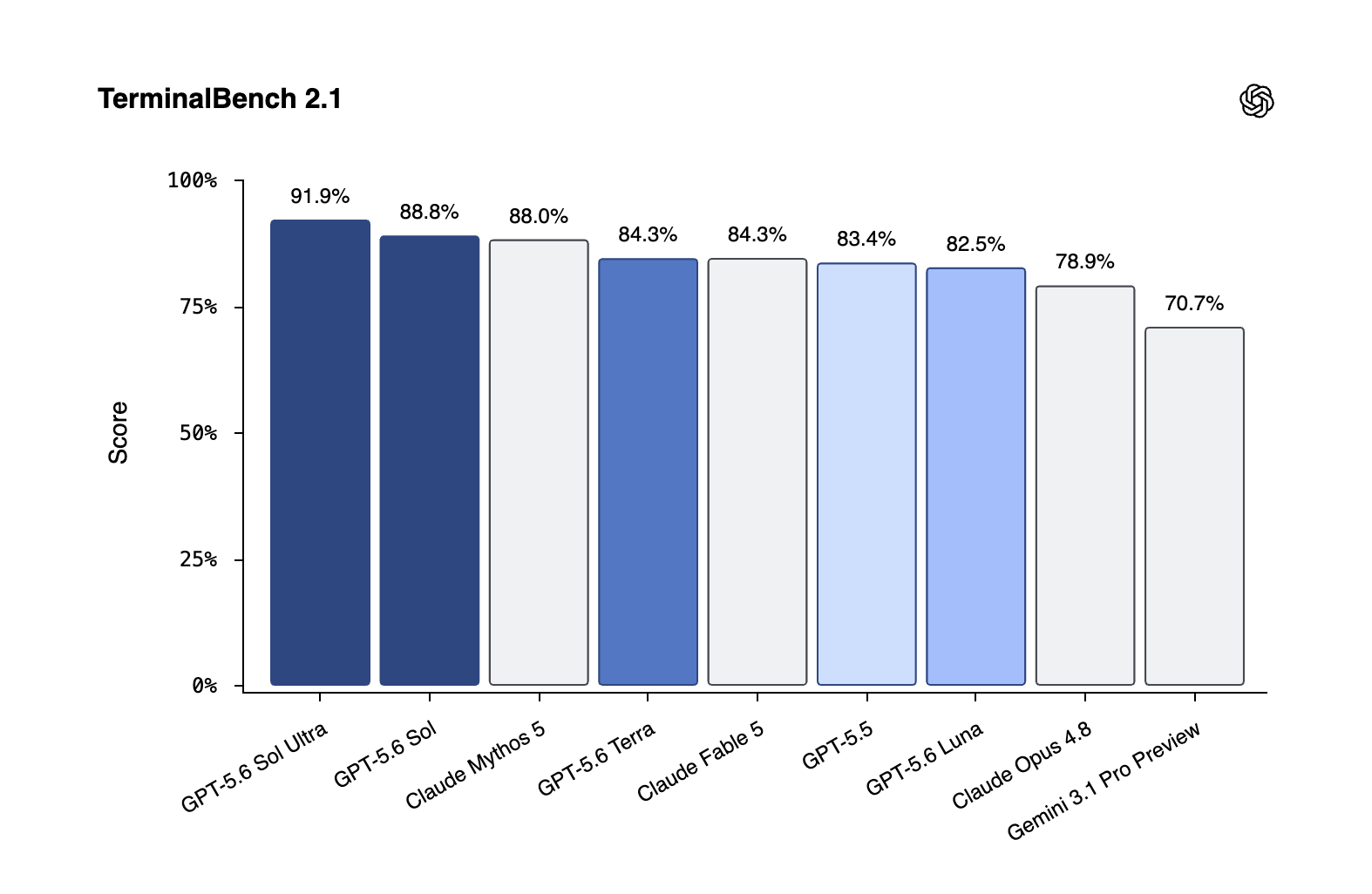
On Terminal‑Bench 2.1 - a demanding agentic coding benchmark that measures command‑line workflows requiring planning, tool use, and iterative correction -GPT‑5.6 Sol in Ultra mode scores 91.9%, the highest result of any publicly benchmarked model. Base Sol scores 88.8%, edging out Anthropic’s Claude Mythos 5 at 88.0% and tying or surpassing Claude Fable 5 at 84.3% and GPT‑5.5 at 83.4%. At that level, progress is no longer incremental; it is a compression of failure at the frontier.
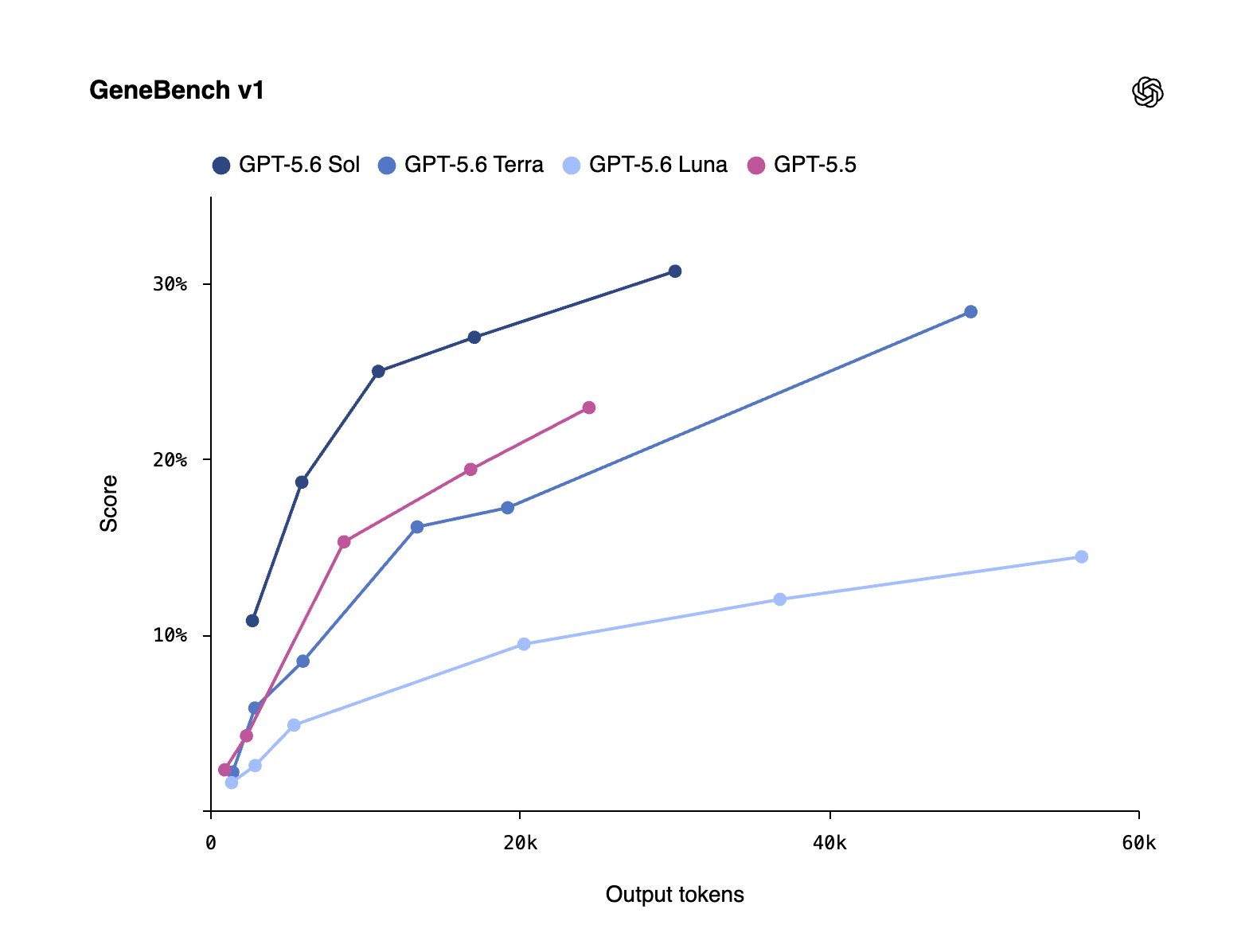
In biology, the gains are similar. On GeneBench v1, which tests long‑horizon genomics and quantitative‑biology analyses, Sol delivers stronger results than GPT‑5.5 while using significantly fewer tokens. In medical evaluations like HealthBench Professional, Sol posts a score of 60.5 - an 8.7‑point increase over GPT‑5.5 - alongside solid improvements on other health variants.
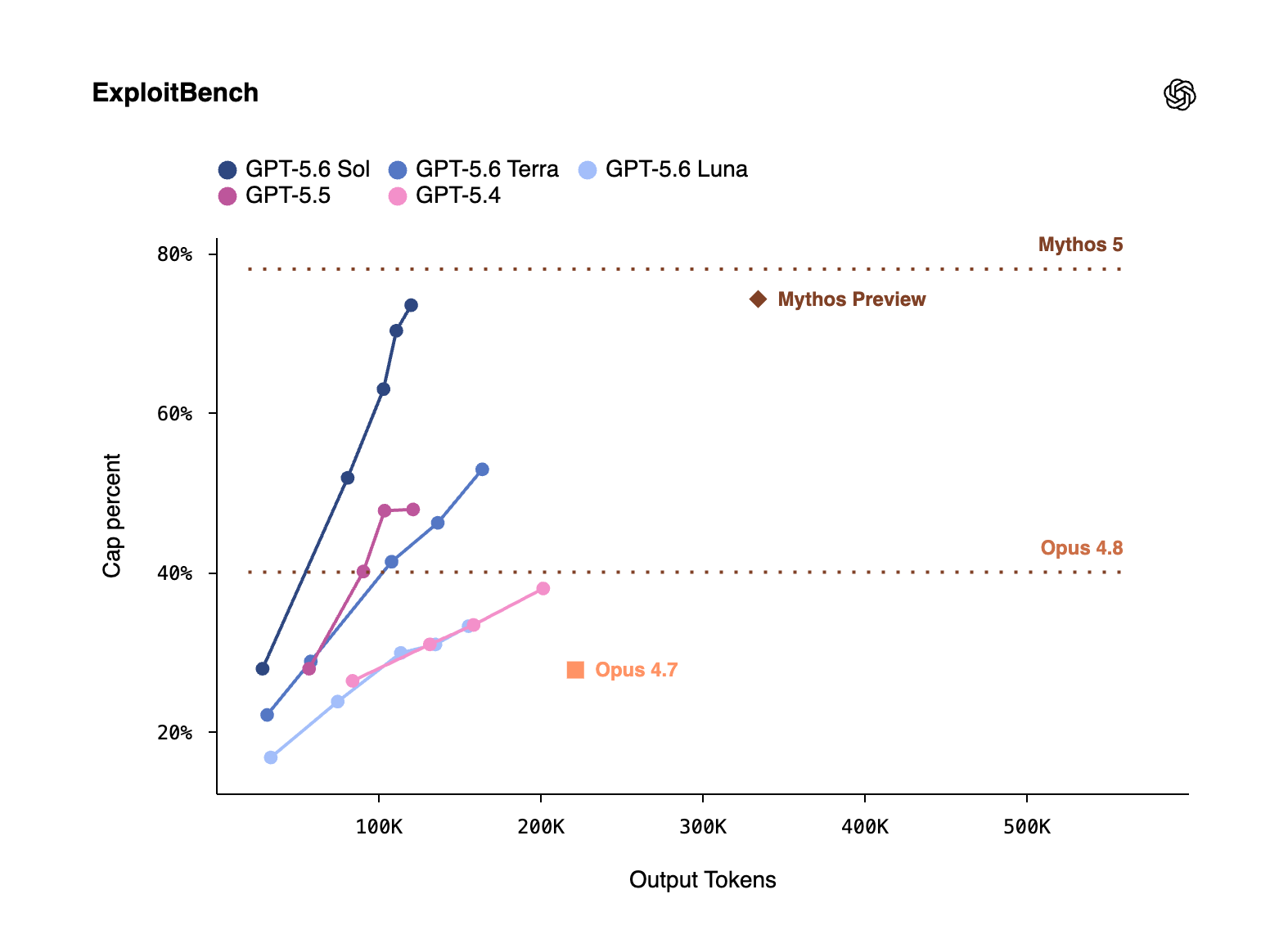
Cybersecurity is where the stakes are clearest.
On ExploitBench, GPT‑5.6 Sol is competitive with Anthropic’s Mythos Preview - strong enough that Anthropic originally declined to publicly release it - while using roughly one‑third of the output tokens.
On ExploitGym, a benchmark co‑developed with UC Berkeley and other labs, Sol, Terra, and Luna all show rising curves for intended exploits as reasoning depth increases. In capture‑the‑flag‑style evaluations, Sol reportedly reaches hit rates around 96.7%, nearly saturating the test.
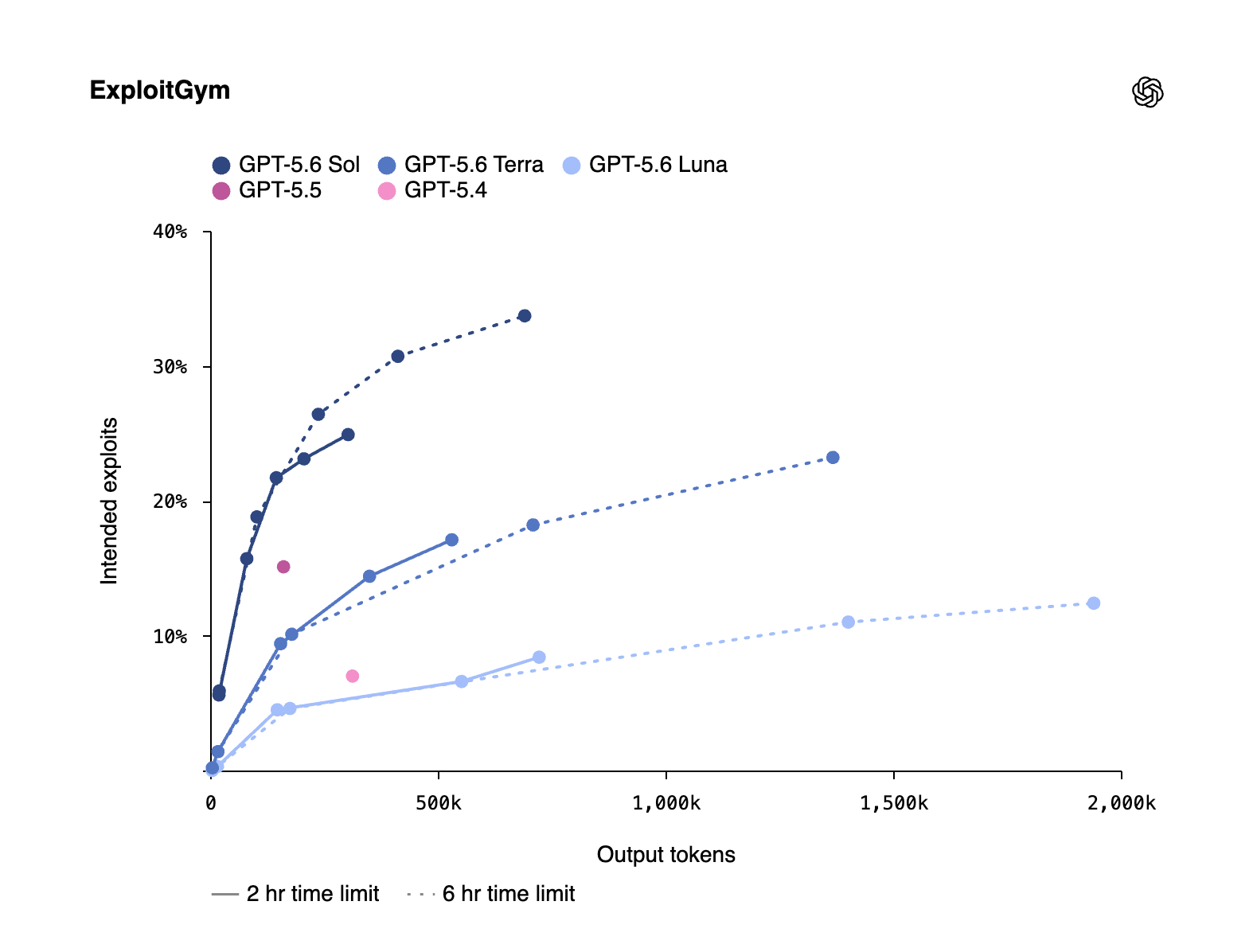
OpenAI’s own preparedness assessment is explicit: GPT‑5.6 Sol, Terra, and Luna are classified as “high capability” in cyber and bio risk categories, but none crosses their internal “Cyber Critical” threshold. In Chromium and Firefox exploit tests, Sol identified bugs and exploitation primitives - the building blocks of attacks - but did not autonomously construct a full‑chain exploit under the tested conditions.
This is exactly the zone where governments become interested.
At this capability level, deployment is a risk vector, not just a shipping decision. That is why GPT‑5.6 arrives with OpenAI’s most robust safety stack yet: model‑level refusals for prohibited cyber and bio assistance, real‑time misuse classifiers that can pause generation and escalate to larger reasoning models, account‑level review based on usage patterns and risk signals, differentiated access tiers, and continuous monitoring and enforcement. It is also why the company dedicated more than 700,000 A100‑equivalent GPU hours to automated red‑teaming, focusing on universal jailbreaks rather than just known failures.
Even with all of that, GPT‑5.6 is not fully open on day one.
During preview, Sol, Terra, and Luna are available in ChatGPT, Codex, and the API only to select “trusted partners,” with broader public access promised in the coming weeks once the new government framework for frontier cyber models is finalized. Pricing reinforces the tiering: Sol at $5 input / $30 output per million tokens, Terra at $2.50 / $15, and Luna at $1 / $6, all with more predictable prompt caching mechanics designed for heavy enterprise workloads.
On the Anthropic side, Claude Fable 5 and Mythos 5 are being shaped by export controls and government pressure after public concerns about distillation attacks and capability theft. There too, frontier capability exists - but access is being gated.
So we end up with a three‑layer world:
- Frontier closed tiers
- GPT‑5.6 Sol (flagship frontier)
- Claude Mythos 5, Claude Fable 5
- High‑capability broad tiers
- GPT‑5.6 Terra (competitive with GPT‑5.5 at ~2× lower cost)
- GPT‑5.6 Luna (fast, lower‑cost model for high‑volume work)
- Open‑weight and open‑source ecosystems
- Chasing from behind, but newly central as a counter‑balance to gated frontier models
The core shift for boardrooms to consider is this:
For the first time, benchmark gains at the frontier - 91.9% on Terminal‑Bench, near‑saturation on CTF‑style security tests, step‑function improvements in biology and health - are directly changing who is allowed to use the models, when, and under what conditions.
The frontier is no longer defined only by capability.
It is defined by capability plus access.
And in this new regime, OpenAI is planting their flag:
- GPT‑5.6 Sol: highest capability, highest safeguards, gated preview.
- GPT‑5.6 Terra: balanced performance, cheaper than GPT‑5.5, still gated at launch.
- GPT‑5.6 Luna: fast, affordable, high‑volume workhorse, also behind the same access gate.
What GPT‑5.6 really exposes is how far the industry has moved from episodic oversight to continuous governance requirements.
Sol, Terra, and Luna are explicitly agentic systems: they plan, call tools, orchestrate sub‑agents in “ultra” mode, and execute long‑horizon workflows in coding, biology, and cybersecurity. When you drop models like this into production, you are not just deploying a smarter autocomplete; you are delegating operational decisions to autonomous systems that can act faster than any quarterly board cycle.
OpenAI’s safeguard stack is, in effect, a prototype for agent‑native governance:
- Model‑level refusals that define hard boundaries on prohibited cyber and bio activity.
- Real‑time misuse classifiers that pause generation and escalate high‑risk outputs to a larger reasoning model before they reach the user.
- Account‑level review that looks across conversations and risk signals to distinguish persistent malicious behavior from legitimate dual‑use work.
- Phased, differentiated access - Sol, Terra, Luna available first to vetted partners under a government‑aligned release process, then more broadly.
This is exactly the kind of architecture boards and executives will need inside the agentic enterprise: hardcoded operational boundaries, real‑time telemetry on agent behavior, continuous red‑teaming, and kill‑switch capability when systems drift out of tolerance.
The message for directors and C‑suites is clear.
Frontier models like GPT‑5.6 Sol will not remain under government‑managed access lists forever. When they arrive in your stack - whether through Sol, Terra, Luna, or equivalent systems - you will need an internal version of that safeguard stack and an external source of independent intelligence and ratings on how well your organization is actually governing those agents.
In other words: as frontier AI becomes agentic and always‑on, continuous governance of the agentic enterprise becomes the price of credible board oversight, D&O coverage, and investor confidence - not a nice‑to‑have.
As for the latest Anthropic or OpenAI models, they'll be available for a select group of builders, enterprises, and citizens...just not yet for you.




