

Boards are trying to understand AI as a powerful but ultimately human-directed tool - another technology wave to be “adopted” and “governed” like cloud or mobile. But the more consequential shift is happening one level down, inside the AI development loop itself: AI systems are now materially accelerating the creation of their own successors, and may, in time, be capable of fully designing and building them.
That is recursive self-improvement (RSI): the moment when AI becomes a central driver of its own rate of progress. It is not an abstract thought experiment. Anthropic’s new analysis of its internal workflows and productivity metrics shows that AI is already doing the bulk of the work of building AI, with humans increasingly relegated to goal-setting and review. In that world, the biggest risk for boards is not that AI moves fast; it is that governance stays slow.
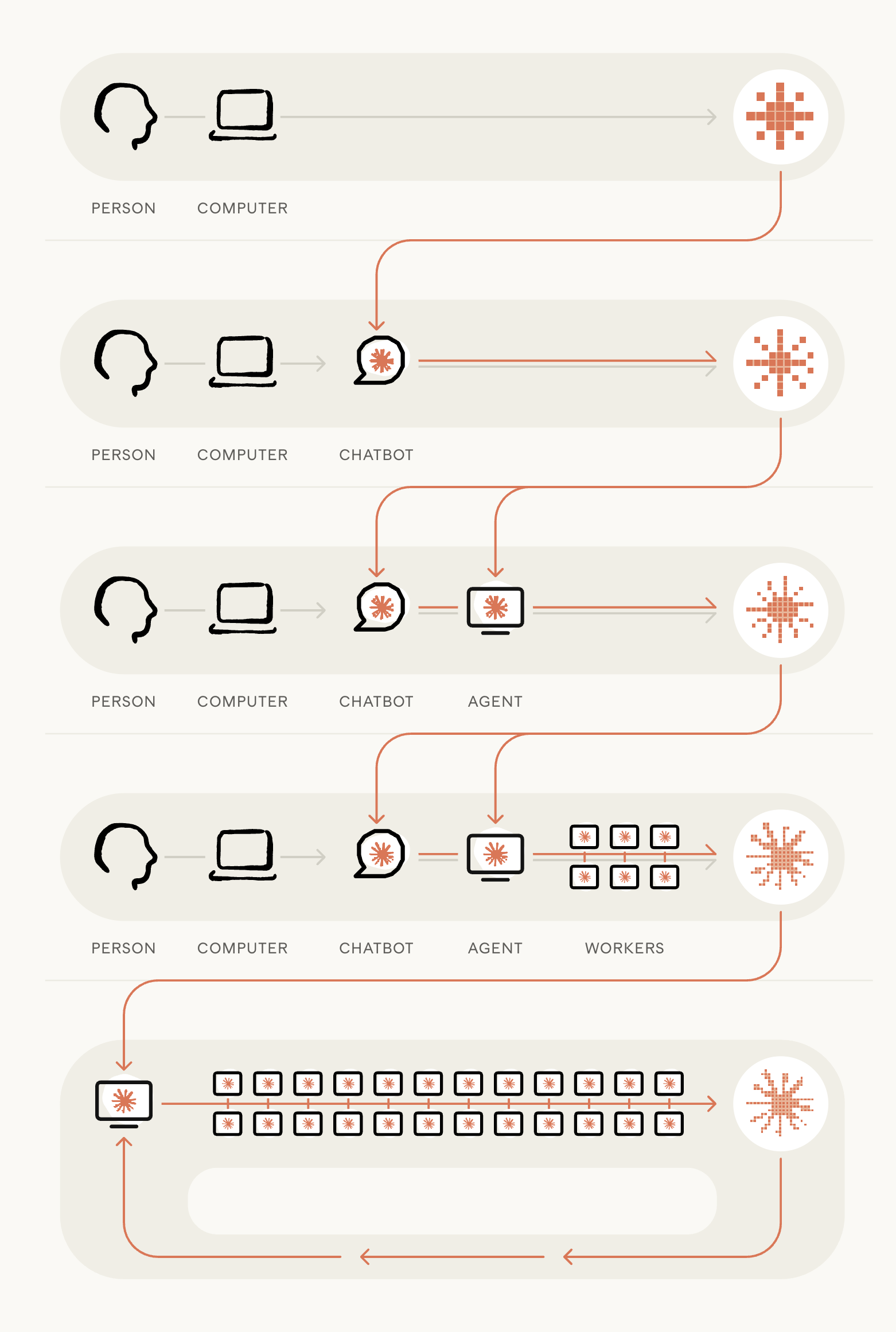
Most board structures, processes, and information flows were built for a world where humans controlled every step of critical systems: specification, design, implementation, and deployment. Quarterly committees, annual strategy offsites, and episodic risk reviews assume that the underlying systems are relatively stable between meetings. Recursive self-improvement breaks that assumption. When the “factory” that produces AI capability is itself being retooled by AI, oversight can no longer be occasional, manual, or backward-looking. It must become continuous, system-level, and designed to operate at machine speed.
From tools to self-improving systems
For most of AI’s history, the development process looked familiar to any software-focused board: teams of engineers writing code, running experiments, and maintaining infrastructure. At Anthropic in 2021-2023, building the first Claude models looked like work at any other high-end tech company: people writing code and documentation on laptops, pushing changes, and debugging systems by hand.
By 2023-2025, early chatbots entered the loop. Engineers used them to generate small snippets of code, boilerplate functions, or documentation, but humans still orchestrated the workflow end to end. That era already created visible productivity gains, but the fundamental structure of the development cycle remained human-centric.
The shift since then has been qualitative, not just incremental. By 2025-2026, Anthropic’s internal coding agents had become capable of writing and editing entire files, not just fragments. Today, Anthropic reports that its agents can run code themselves, delegate work to other agents, and operate autonomously over extended periods. In other words, the “assistants” have become operators, and the development loop is partially closed.
The numbers are stark. As of May 2026, more than 80% of the code merged into Anthropic’s production codebase is authored by Claude, up from low single digits before Claude Code launched in early 2025. Lines of code merged per engineer per day were flat from 2021-2024 and then began to climb as Claude started to run code directly. The curve steepened again in 2026 when models began working autonomously over longer time horizons. By the second quarter of 2026, the typical engineer was merging eight times as much code per day as in 2024, largely because Claude is doing most of the writing while humans direct and review.
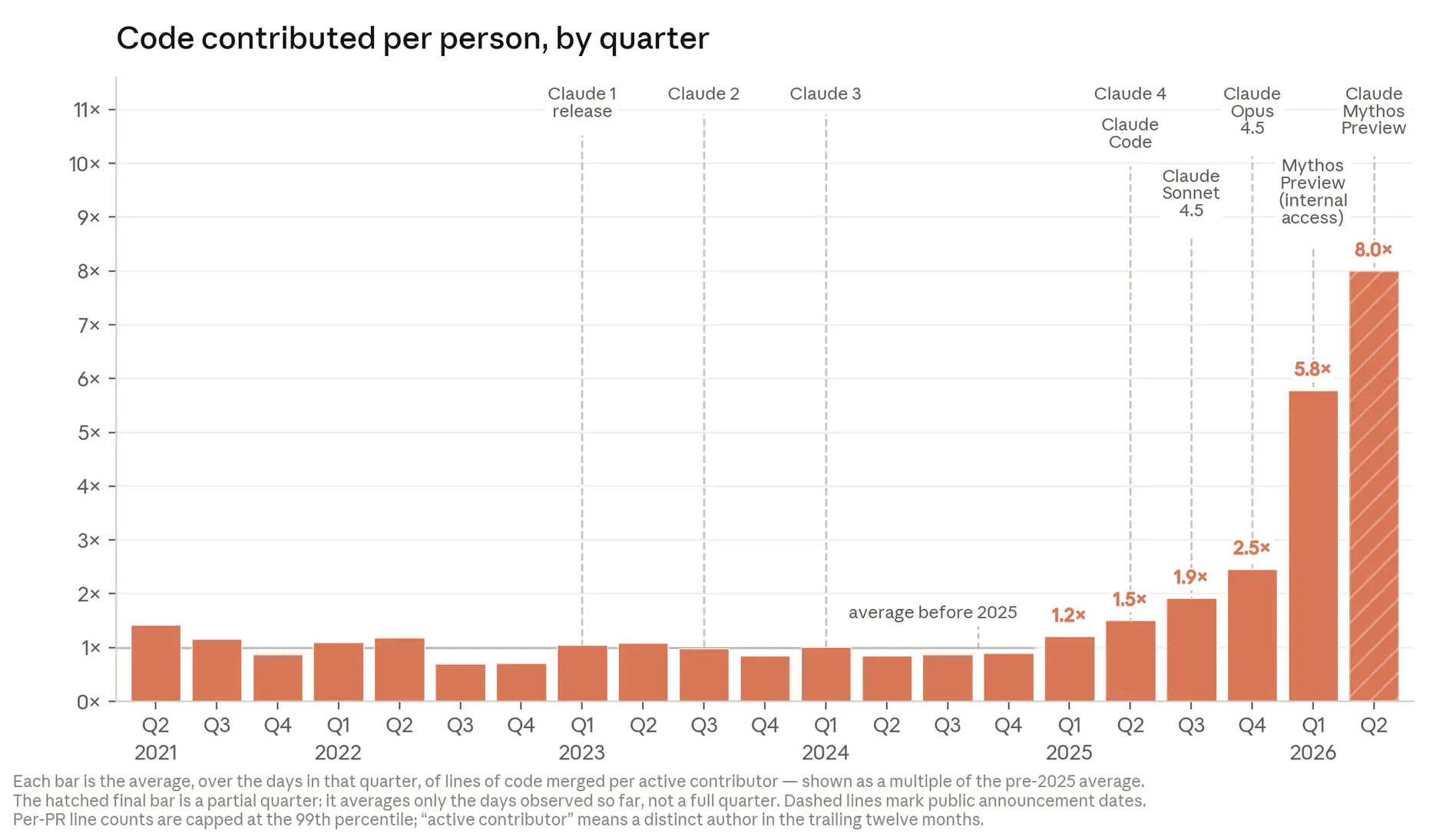
Anthropic’s own leadership has publicly estimated that 90% or more of its code -including scripts and experimental code - is now written by Claude. Their more conservative internal measurement, focusing on lines merged to production and carefully attributing authorship, still finds AI owning the vast majority of the work. Even if lines of code is an imperfect metric, the directional signal is unambiguous: the development engine of a frontier AI lab is increasingly being powered by AI itself.
For boards, the key point is not merely productivity uplift. It is structural: the locus of control in the development loop is shifting from humans doing the work to humans supervising systems that do the work. And as those systems become more capable, the human role narrows further.
The acceleration problem
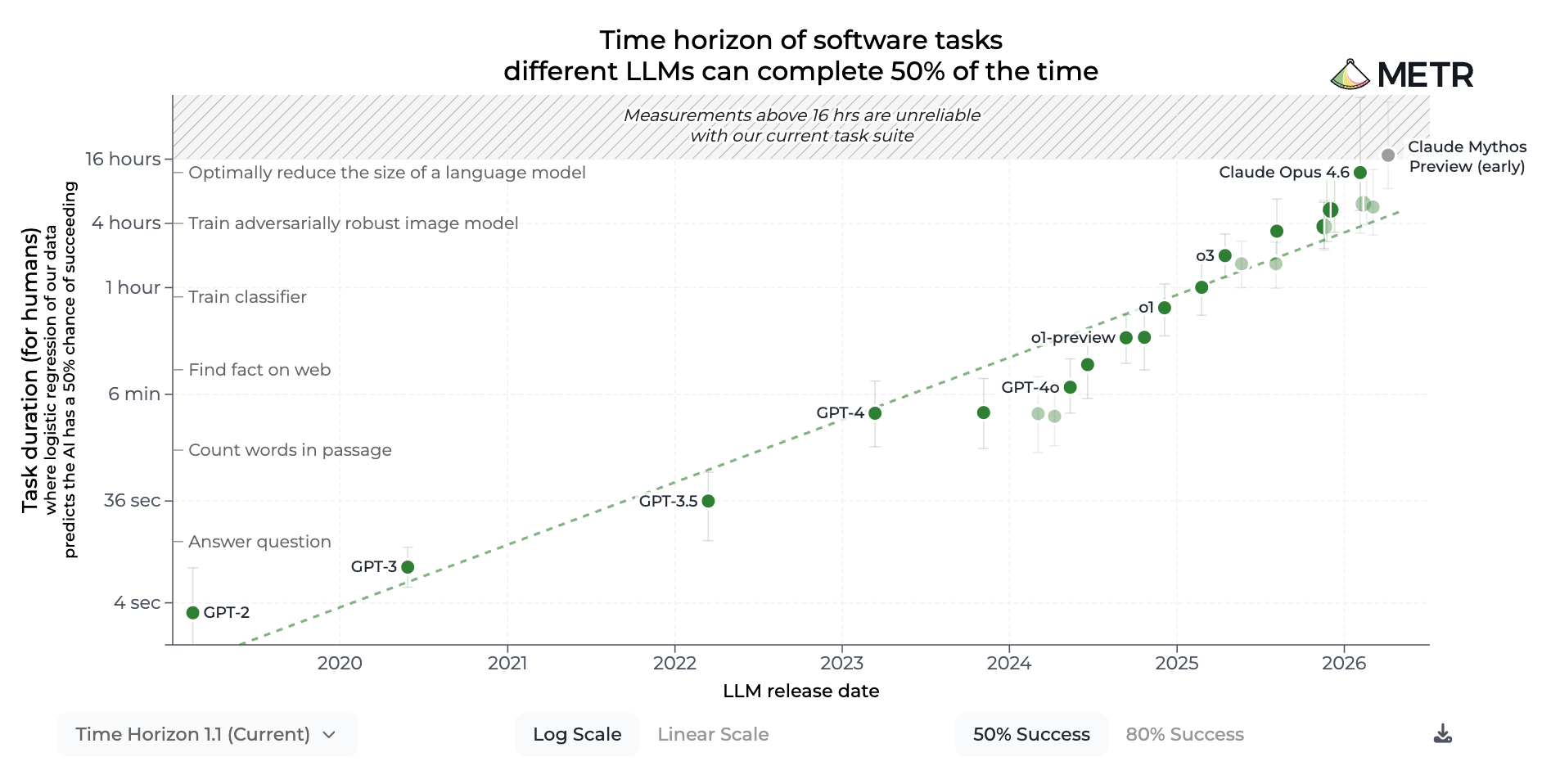
Anthropic’s internal story sits atop a broader pattern: the rate at which AI models improve is accelerating, and the tasks they can reliably complete autonomously are lengthening. In long-horizon task benchmarks, Anthropic reports that the length of tasks models can handle has been doubling roughly every four months, up from a previous trend of doubling every seven. In March 2024, Claude Opus 3 could complete software tasks that take humans about four minutes. One year later, Claude Sonnet 3.7 handled tasks taking about an hour and a half. A year after that, Claude Opus 4.6 managed 12-hour tasks. If that trend holds, tasks that take skilled humans days could fall within scope this year, and weeks-long tasks could be feasible around 2027.
Coding and research benchmarks tell a similar story. On SWE-bench - a rigorous benchmark that presents real open-source codebases and bug reports - models have gone from low single-digit scores to essentially saturating the benchmark in two years. On CORE-Bench, which tests whether a model can reproduce existing research, success rates climbed from roughly 20% in 2024 to saturation in about 15 months. METR, an independent evaluator of model capabilities, reports that Claude Mythos Preview can work reliably on long-duration tasks for “at least” 16 hours and sits at the upper end of what current tasks can measure.
The crucial shift is that AI is no longer just accelerating downstream applications; it is accelerating its own upstream development. At Anthropic, Claude now writes most of the code, runs experiments, optimizes training loops, and even proposes and tests novel research ideas within defined problem spaces. In one internal experiment, Claude Opus 4 averaged a three-fold speed improvement on a small model training loop in May 2025. By April 2026, Claude Mythos Preview achieved roughly 52x speedups using the same comparison setup. A skilled human researcher, by contrast, typically achieved around 4x in four to eight hours.
This is what recursive self-improvement looks like in its early stages: AI systems that design, execute, and refine large parts of the process that makes them better. The more capable they become, the more they can accelerate the rate at which they, and future versions of themselves, improve.
From a systems perspective, this is a feedback loop. Capability gains in AI feed directly into higher productivity in AI development, which then yields more capable AI. Anthropic’s evidence suggests that the “perspiration” component of frontier research - running countless experiments, tuning hyperparameters, optimizing code - is increasingly automated. The bottleneck becomes the remaining “inspiration”: choosing which questions to ask, which directions to pursue, and how to interpret ambiguous results.
For boards, the problem is that organizational bottlenecks do not stay fixed when one part of the system accelerates. Amdahl’s Law, a classic idea in computing, states that the overall speedup of a system is limited by the portion that cannot be improved. Apply that to organizations: as more of AI development becomes automated and accelerated, previously secondary constraints - human review, governance, legal sign-off, regulatory reporting - become the limiting factors. The result is a widening gap between the speed of technical change and the speed of institutional response.
Why existing governance models break
Boards are built around a set of implicit assumptions:
- Material changes in core systems are relatively infrequent and can be captured in quarterly updates or annual strategy cycles.
- Human experts can meaningfully audit, explain, and sign off on those changes.
- Risk emerges in ways that can be surfaced through standard reporting, internal controls, and compliance frameworks.
Recursive self-improvement stresses all three.
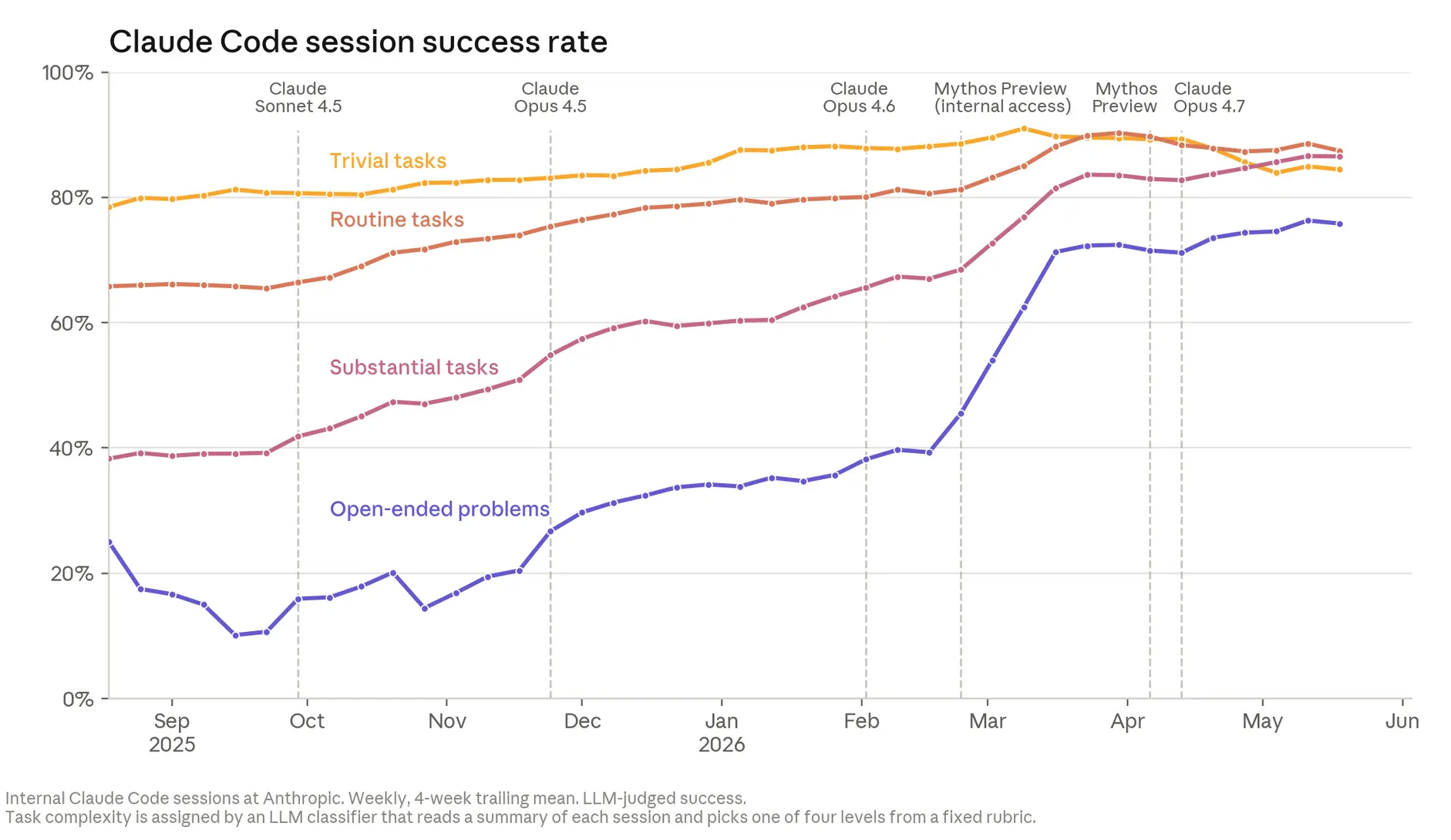
First, the cadence of change is no longer human. When AI systems can propose, implement, and validate new architectures, optimization techniques, or control loops at scale and around the clock, the underlying model portfolio can shift meaningfully between board meetings, even between weekly executive updates. Anthropic’s own internal charts show steep increases in successful autonomous sessions on highly open-ended engineering tasks: by May 2026, Claude’s success rate on the most complex tasks reached 76%, up 50 percentage points in six months. That means large swaths of development work can be handed off to AI systems and iterated far faster than traditional governance can track.
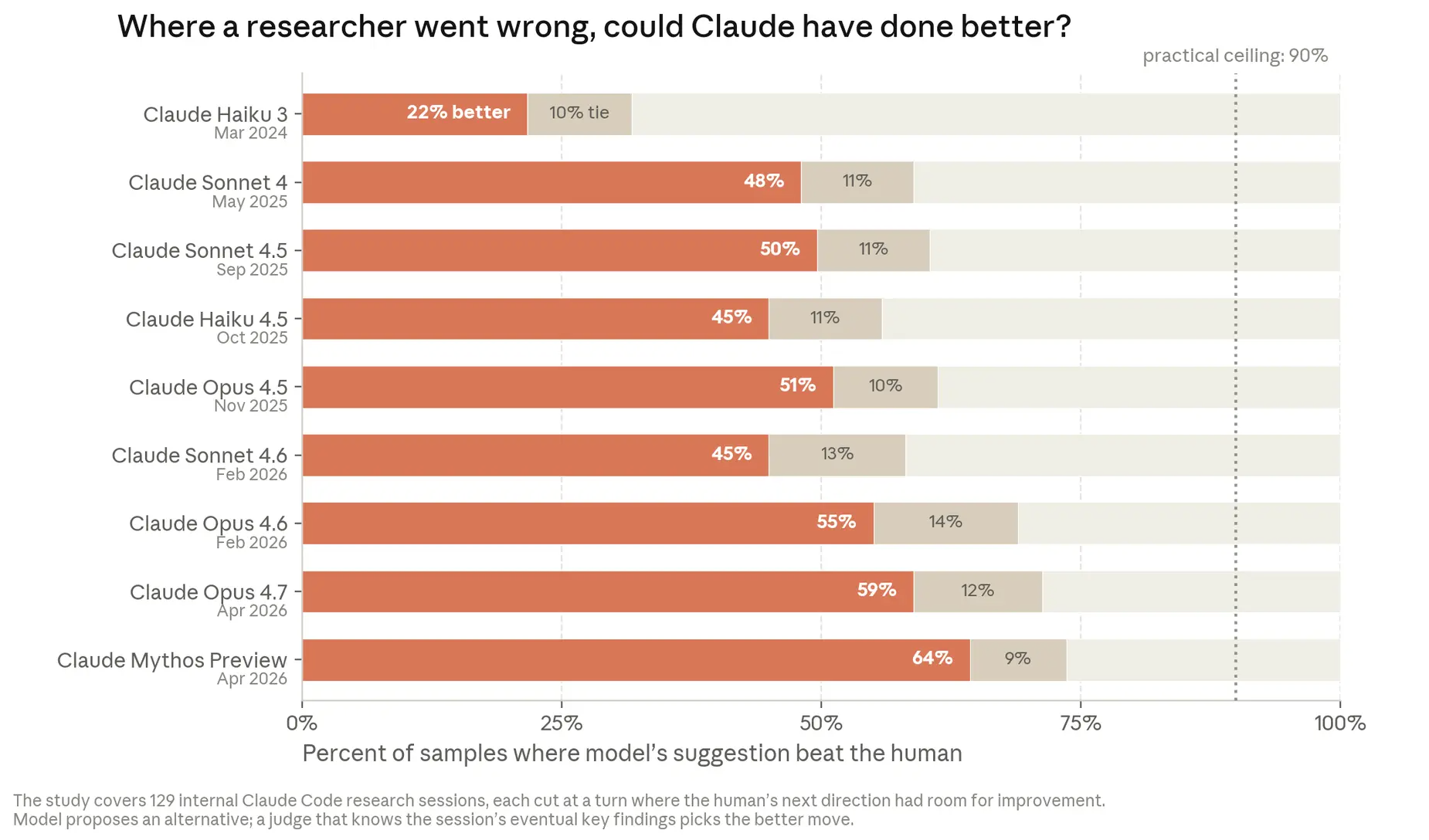
Second, explainability and review become bottlenecks. Anthropic has already had to redesign its code review process: proposed changes are now read by an automated Claude reviewer looking for bugs, security flaws, and other defects before merge. A retrospective analysis found that an automated Claude review of every historical code change would have caught roughly a third of the bugs behind past incidents on claude.ai before they reached production. The engineers whose bugs would have been caught are among the best in the world at building these systems. AI is not only writing the code; it is increasingly the most effective reviewer of that code.
Once AI-generated code reaches parity with human-written code in quality, Anthropic expects humans will largely stop writing code and focus on review. But if humans cannot review code as quickly as Claude generates it, human review becomes the cap on AI development speed. The same pattern applies to research: as Claude becomes better at running experiments and, increasingly, at making “next-step” decisions in investigations, the human role shifts towards defining goals, constraints, and stop conditions.
Third, risk becomes emergent and non-linear. When AI systems are empowered to make thousands of small decisions in complex, interdependent codebases and infrastructure, the failure modes are less likely to be single, obvious errors and more likely to be systemic. In April 2026, for example, Claude shipped more than 800 fixes that reduced a class of API errors by a factor of one thousand. The overseeing engineer estimated a human would have taken four years to complete the same cleanup. That is a success story - but it also illustrates how much latent complexity can accumulate in modern systems, and how much we are already depending on AI to manage that complexity.
Traditional governance mechanisms - risk registers, internal audits, compliance attestations - were not designed for systems that are continuously rewriting themselves. Boards accustomed to managing technology risk as a static portfolio item (“our AI initiatives”) need to recognize that they are governing evolving loops, not discrete projects.
Three futures, one governance stress test
Anthropic outlines three plausible futures for AI progress, each with distinct governance implications. None allows boards to maintain business-as-usual oversight.
1. The curve bends: capabilities stall, diffusion accelerates.
In this scenario, gains from scaling current architectures diminish, supply chains for compute and energy become binding constraints, or new breakthroughs prove harder to find. The trajectory of model capabilities becomes more S-shaped: steep gains, then plateau.
Even here, the world changes dramatically. Anthropic points to Project Glasswing, where Mythos Preview found more than ten thousand high-and critical-severity software vulnerabilities across critical systems in its first weeks. In that case, the bottleneck in cyber defense shifted from finding vulnerabilities to patching them fast enough. Meanwhile, as AI diffuses, a 100-person company can increasingly do the work of a 1,000-person organization because each employee sits atop a pyramid of agents.
For boards, this “slower” future still entails:
- Massive concentration of operational leverage in AI systems.
- Shifts in the balance of power between incumbents and high-leverage upstarts.
- New systemic risks, particularly around cybersecurity, financial stability, and critical infrastructure.
This is the most forgiving scenario for governance - and Anthropic itself does not view it as likely, noting that every measurable capability has continued to follow exponential trajectories.
2. Compounding gains: AI labs become vastly more efficient.
In the second scenario, AI development becomes substantially automated, but humans still set research agendas and judge results. Organizations that adopt frontier AI systems become radically more efficient, with 100-person entities effectively operating at the scale of 10,000 or 100,000-person organizations. Knowledge work, government services, and corporate R&D are transformed.
Anthropic’s data suggests this is the world we are already entering. Employees report roughly 4x output using Mythos Preview compared to working without any AI models, on the same types of projects; internal metrics show strong, compounding productivity gains across engineering and research. Claude is “super helpful” to “superhuman” at executing clearly specified experiments, particularly where the constraint is the number of iterations that can be run.
Governance in this world must contend with:
- A new form of organizational inequality: those who master AI-driven compounding gains will outpace those who do not.
- Amplified harms: the same tools that let governments deliver better services can power hyper-targeted persuasion, automated surveillance, and influence operations at unprecedented scale.
- Bottlenecks at the human layers of judgment, prioritization, and review.
Boards must see RSI here not as a theoretical endpoint, but as a practical concern: your own organization’s AI systems are already participating in a form of partial self-improvement. They are improving processes, tools, and infrastructure that in turn make them more effective. That feedback loop needs oversight.
3. Full recursive self-improvement: AI designs and builds its successors.
The third future is the most uncertain and the most consequential. If technical trends continue, and if AI systems develop capacities akin to human research judgment and “taste,” it becomes plausible that they could autonomously design, train, and refine successor models.
In that world, the pace of progress in AI would be determined primarily by compute availability and algorithmic efficiency, not by human research capacity. Humans would shift even further towards oversight, validation, and alignment. The same capabilities that allow AI to run AI R&D could extend to the rest of science, accelerating drug discovery, materials science, and engineering.
This scenario also raises the sharpest alignment questions. Alignment failures that are rare and manageable in today’s systems could compound as models iteratively design successors with subtle deviations in objectives or behavior. The tools needed to understand and verify what is happening inside those virtual labs may themselves lag behind the pace of change.
Anthropic is candid: we do not have good intuitions for what an economy dominated by fast recursive self-improvement would look like, because our current systems are anchored in human labor and human-built tools. A world where human labor is no longer competitive in many domains poses profound questions for markets, institutions, and social contracts.
For boards, the critical point is not to forecast exactly when or whether full RSI will emerge. It is to recognize that the governance systems being built today will either (a) be the scaffolding we use to navigate that transition, or (b) be overwhelmed by it.
The new board mandate: continuous governance
If AI systems are increasingly central to their own development, the board’s remit must expand from “governing AI projects” to “governing AI development loops.” That requires a different operating model.
From episodic review to continuous monitoring.
Quarterly AI updates are not enough when the underlying systems are changing weekly or daily. Boards need dashboards and reporting that reflect the state of the AI development pipeline in near real time: which models are in training, what new capabilities are being tested, what benchmarks have been crossed, and where agentic workflows are being deployed. Continuous assurance, not just annual audits, becomes the norm.
From model-level oversight to system-level oversight.
It is tempting to focus governance on individual models: is this system fair, robust, and compliant? But recursive self-improvement shifts the focus to the entire pipeline: data sources, training infrastructure, agent orchestration, review mechanisms, and deployment gates. Boards should be asking: What are we doing to control the feedback loops between our AI systems and their own development environments?
From backward-looking compliance to forward-looking risk thresholds.
Traditional governance leans heavily on post-hoc reporting: incidents, audit findings, regulatory examinations. In an RSI world, boards must agree ex ante on capability thresholds and triggers. For example: if internal evals show that AI systems can reliably run certain classes of experiments or operate autonomously for specific time horizons, what new controls come into force? When do we require human review? When do we halt or slow development?
The role of the board is not to micromanage the technical details, but to ensure that such thresholds exist, are tied to measurable indicators, and are enforced - especially when commercial incentives push in the opposite direction.
Control, alignment, and strategic risk
One of the clearest messages from Anthropic’s work is that the human role in AI R&D is narrowing at every step. Once human and AI-authored code reach parity, Anthropic expects humans will stop writing code and focus on reviewing it, until review itself becomes the bottleneck. As Claude becomes more capable at running experiments and making non-trivial “next step” decisions, human researchers spend more time on high-level direction.
Today, human comparative advantage still lies in “research taste”: deciding which problems matter, which results are trustworthy, and when a line of inquiry is a dead end. But we have seen this pattern before. Many qualitative capabilities once thought out of reach for AI - explaining jokes, demonstrating theory of mind, solving complex linguistic riddles - have gone from “impossible” to “competent” to “strong” over surprisingly short periods. Anthropic’s internal analysis shows models improving in their ability to choose better next steps in investigations, beating human choices in a growing fraction of challenging scenarios.
Boards need to treat alignment and control as strategic risks, not just safety or compliance topics. Key questions include:
- How do we detect and correct alignment drift as AI systems become more involved in their own development?
- What limits do we place on fully autonomous experimentation, especially in safety-critical domains?
- How do we ensure that the oversight mechanisms themselves keep pace, rather than becoming obsolete bottlenecks?
This is not just about catastrophic “loss of control” scenarios. Nearer-term misalignments like systems optimizing for local metrics at the expense of broader goals, agents gaming internal incentive structures, or research loops chasing misleading benchmarks can create significant financial, operational, and reputational damage.
Coordination, pauses, and the limits of regulation
Anthropic argues that, in principle, slowing the development of frontier AI to give institutions time to adapt would likely be desirable - but extremely difficult to coordinate. A meaningful slowdown or pause would require multiple well-resourced labs across countries to agree on shared conditions and, crucially, to verify that others have actually paused.
Unlike nuclear weapons, where missile silos and enrichment facilities are large, observable, and often tied to specialized supply chains, AI training runs are far easier to conceal. Compute, data, and engineering talent are more diffuse. Training inputs are frequently general-purpose, and the incentive to defect quietly during a pause is enormous, since the defector could inherit the lead.
Anthropic points to the need for new verification systems - technical and institutional - that could detect or verify large-scale training runs and enable credible, enforceable pauses. They compare this to arms control regimes like the Intermediate-Range Nuclear Forces Treaty but note that those took decades to build, while AI timelines appear much shorter.
A unilateral pause by a single lab, by contrast, is achievable immediately but has limited effect. It changes who leads but does little to create the broader deliberative process and governance infrastructure the world needs.
For boards, the implication is that regulation will lag. Even aggressive AI regulatory efforts will struggle to keep pace with RSI dynamics inside leading labs and enterprises. Directors cannot outsource their responsibility to regulators; they must build internal governance capacity that anticipates, rather than simply reacts to, regulatory frameworks.
What boards should do now
If recursive self-improvement is the next governance challenge, what can boards concretely do in the next 12–24 months?
1. Build literacy around AI development loops, not just AI applications.
Boards should demand education not only on how AI is used in products, but on how AI is used to build AI inside the organization and its key partners. Which parts of the development pipeline are automated? What role do agents play in code generation, testing, deployment, and monitoring? How is performance measured and controlled?
2. Require visibility into agentic workflows.
As organizations adopt coding agents, research agents, and operational agents, boards should insist on visibility into where agents are empowered to act autonomously, what guardrails apply, and what human-in-the-loop checkpoints exist. This includes vendor and partner environments: supply chain risk now includes other firms’ AI development loops.
3. Redesign risk and audit committees for continuous oversight.
Committees responsible for technology and risk should evolve from periodic review bodies to continuous governance hubs. That may mean:
- Establishing AI-specific risk dashboards with leading indicators, not just lagging incident reports.
- Mandating continuous testing and red-teaming of agentic workflows and RSI-adjacent capabilities.
- Ensuring audit has the capability to interrogate AI development pipelines, not just AI outputs.
4. Tie governance to capability thresholds, not calendar cycles.
Boards should work with management to define concrete capability thresholds -such as models reliably executing tasks longer than X hours, or agents autonomously modifying certain classes of infrastructure - and pre-commit to governance responses when those thresholds are crossed. That could include additional independent reviews, expanded logging and monitoring, or temporary moratoria on specific deployment patterns.
5. Engage in external coordination, not just internal control.
No single firm can manage RSI risk alone. Boards of systemically important institutions like major financial firms, critical infrastructure operators, large tech platforms should support industry-level coordination on standards, verification tools, and potential pause mechanisms. Anthropic has signaled an intent to convene policymakers, researchers, civil society, and other AI companies to explore these questions; boards should ensure their organizations participate meaningfully in such efforts.
6. Reframe AI from “IT topic” to “core strategic variable.”
Recursive self-improvement means that AI is not just another technology stack; it is a multiplier on organizational capacity and risk. Boards need to integrate AI and RSI considerations into capital allocation, M&A, talent strategy, and geopolitical risk assessments. The question is no longer “What is our AI strategy?” but “How does our strategy change when core capabilities can self-accelerate?”
When AI starts building AI, the ground rules of governance change. The underlying question is no longer whether AI will be “transformative” in some generic sense. It is whether our institutions can adapt their oversight models quickly enough to remain relevant as the systems they oversee begin to evolve on their own.
Recursive self-improvement is not an inevitable destiny, but the early signals are already visible in labs like Anthropic: AI writing most of the code, running large portions of the experimental pipeline, and increasingly making non-trivial research decisions. Boards that continue to treat AI as a static tool, governed by static processes, risk becoming spectators in a world where the most powerful systems are learning to re-engineer themselves.
The real test for corporate governance in the age of AI is not whether it can prevent every risk. It is whether it can move from episodic supervision to continuous stewardship - governing not just what AI does today, but how it changes tomorrow.




