

The internal codename was "Spud." The public name is GPT-5.5. Seven weeks after GPT-5.4 shipped, OpenAI has reclaimed the public-model benchmark crown from Anthropic's Claude Opus 4.7 (released exactly seven days ago) and Google's Gemini 3.1 Pro. GPT-5.5 even narrowly beats Anthropic's restricted Claude Mythos Preview on Terminal-Bench 2.0, a statistical tie that would have been science fiction a year ago.
Alongside the model, OpenAI also launched Workspace Agents, the declared successor to the GPT Store, which turns Codex into an enterprise operating layer.
The Super App Thesis Goes Public
OpenAI President Greg Brockman described GPT-5.5 as "one step" toward the kind of computing OpenAI expects in the future and, more tellingly, as an additional step toward what he and Sam have been quietly building: a "super app" that combines ChatGPT, Codex, and OpenAI's AI browser into a single unified service. The target is the enterprise, and the reasons are pretty obvious. Anthropic has been leading the way in the enterprise and their combination of their Claude Code, Claude Co-Work, and Claude AI chatbot all into one integrated super app has taken the world by storm. Everyone is trying to catch up to what Anthropic has done and this is a major step forward by OpenAI.
This matters because since the release of ChatGPT 3.5 on November 30, 2022, OpenAI has been the innovator and trendsetter. Its spent three years being the most capable AI frontier lab, but arguably the least focused as well. Consider the sprawl: ChatGPT, GPTs, Sora, DALL-E, GPT Image, Image 2, Whisper, Advanced Voice, Canvas, Projects, Operator, Memory, Deep Research, Scheduled Tasks, Codex, ChatGPT Agent, and the enterprise stack layered on top of all of it. Much of this was Sam testing surface area. Much of it was the "everything app" thesis: one product for a twelve-year-old writing an essay, a cardiologist reading a scan, a hedge-fund analyst modeling a trade, and a Fortune 500 CIO standing up internal automation.
What changed this week is the pairing. Given the success that Anthropic has had with Claude Code, it is clear to everyone now that coding is the big unlock. It should be no surprise that GPT-5.5 is explicitly a computer-use model. The launch testimonials come from Cursor , Cognition , NVIDIA (NASDAQ: NVDA), Harvey , Databricks , and Box (NYSE: BOX). Eighty-five percent of OpenAI's own employees now use Codex weekly. Workspace Agents is the operational surface on top: shared, remembered, permissioned, scheduled, Slack-deployable, and admin-monitored through a Compliance API. GPTs are officially being deprecated in favor of this surface.
That is not a consumer product. That is enterprise software wearing a chat interface, and OpenAI finally has the conviction to say so out loud.
What the Numbers Actually Say
On the benchmarks that matter for agentic work, the jump is real. GPT-5.5 hits 82.7% on Terminal-Bench 2.0, which tests multi-step command-line workflows. Opus 4.7 scored 69.4% on the same benchmark last Thursday. Mythos Preview, held back by Anthropic on cybersecurity grounds and unavailable for commercial use, lands at 82.0%. GPT-5.5 narrowly beats it in the public arena.
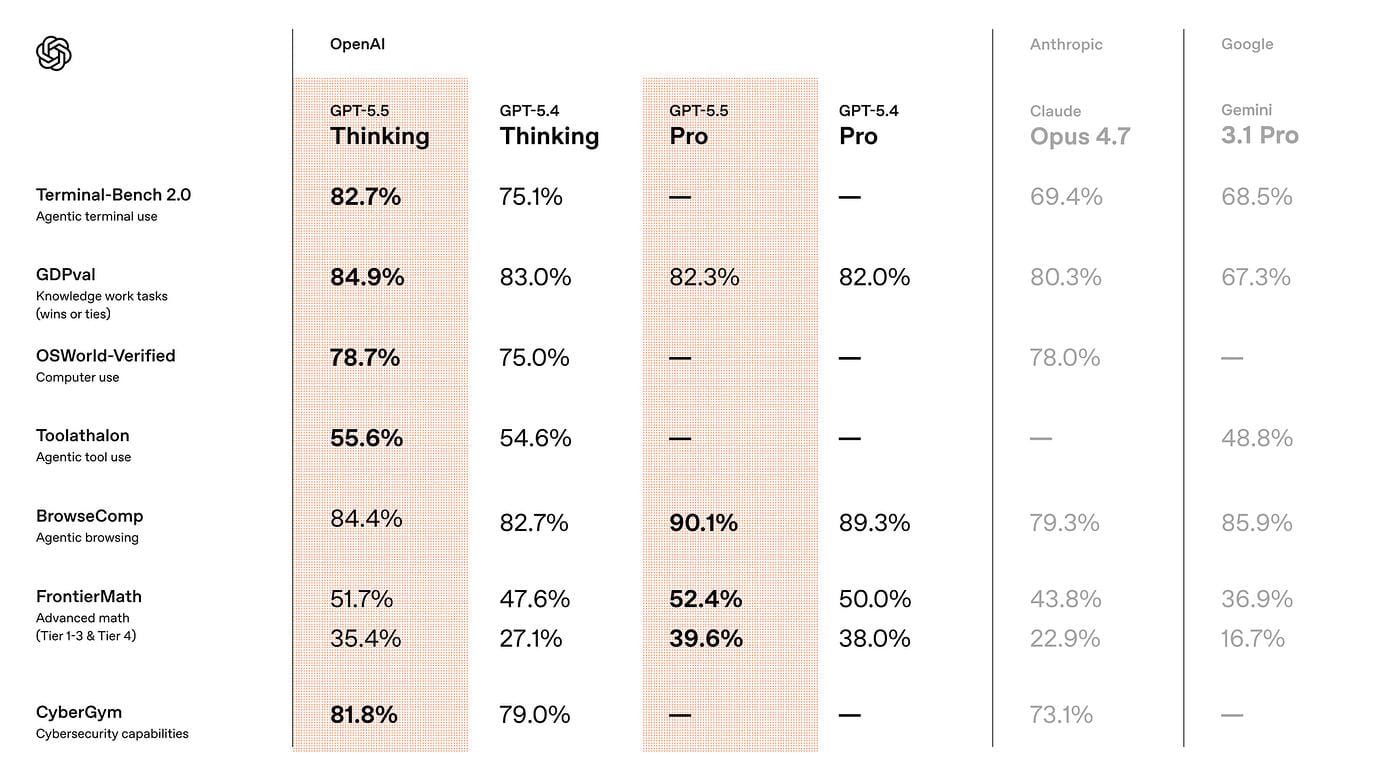
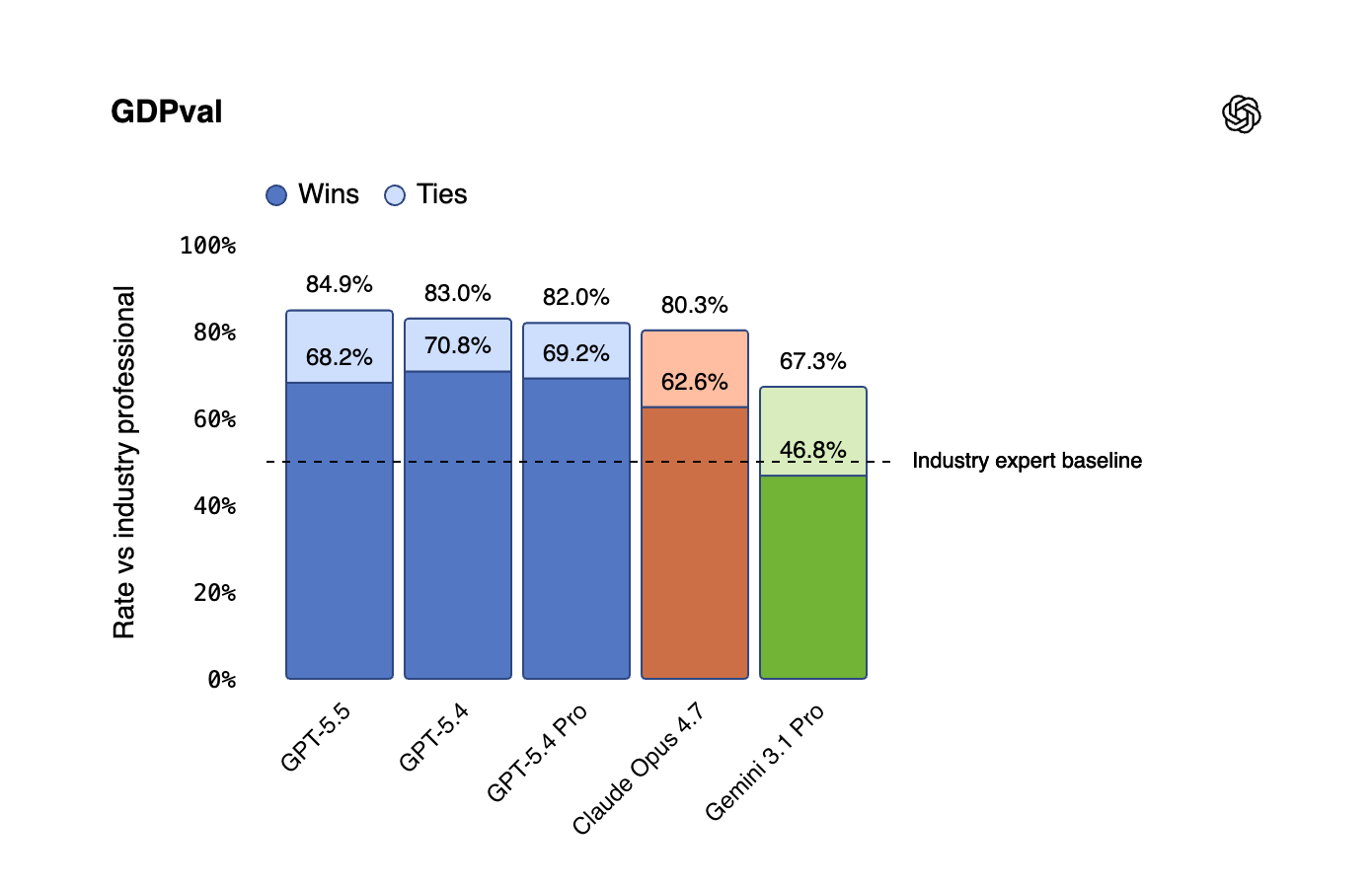
On GDPval, which measures knowledge work against industry professionals across 44 occupations, GPT-5.5 wins or ties 84.9% of the time. On ARC-AGI-2 it scores 85.0%. On CyberGym, the cybersecurity benchmark, it hits 81.8%. On Expert-SWE, OpenAI's internal benchmark for long-horizon coding tasks with a median human completion time of twenty hours, it substantially outperforms GPT-5.4 while using fewer tokens.
The pricing is the tell. API access, coming "very soon," will run $5 per million input tokens and $30 per million output tokens. That is double GPT-5.4's entry pricing. GPT-5.5 Pro is another six times higher at $30 and $180. OpenAI's framing is that the model is more token-efficient, so cost per completed task stays roughly flat. The correct read for CFOs: sticker prices are going up, the value case is shifting from "cheaper than a human" to "capable of work no model could do six months ago," and the 2026 AI budget your finance team built on 2025 assumptions is already outdated.
On multidisciplinary reasoning without tools, the landscape is tighter. GPT-5.5 Pro scored 43.1% on Humanity's Last Exam without tools, trailing both Opus 4.7 (46.9%) and Mythos Preview (56.8%). OpenAI is winning on agency and computer use. Anthropic is still ahead on pure reasoning. That split is not accidental. It is strategy.
The Cybersecurity Split Is the Real Philosophical Fight
This is where the two leading US labs are drawing a hard line, and boards should pay attention.
Anthropic released Claude Mythos earlier this month to approximately 40 organizations that maintain critical infrastructure, including Apple (NASDAQ: AAPL), Amazon (NASDAQ: AMZN), Microsoft (NASDAQ: MSFT), and Alphabet Inc. (NASDAQ: GOOGL). Dario's argument: models this capable at finding security vulnerabilities need to be distributed narrowly so defenders can patch before adversaries exploit. Mythos has already had a reported unauthorized-access incident, which will sharpen that argument for critics who felt the gating was too loose and for critics who felt it was too tight.
OpenAI has taken the opposite position. GPT-5.5 is going to hundreds of millions of ChatGPT users on day one. Its separate "Trusted Access for Cyber" program, which unlocks GPT-5.4-Cyber and cyber-permissive versions of GPT-5.5 for verified defenders, is being distributed to hundreds of organizations initially and thousands more in the coming weeks. Sam's bet is on democratization: broad defensive capability beats narrow gating.
Neither position is the obviously "right answer". Both are expressions of genuinely different beliefs about how AI safety scales. But the divergence now has real operational consequences for enterprises. If your organization is standardized on Anthropic, you will be gated out of the most powerful model for security work unless you are on the critical-infrastructure list. If your organization is standardized on OpenAI, you get broader access but tighter classifiers on general use. The companies that run multi-model stacks get optionality on both axes. The companies that picked one vendor in 2024 are about to discover they picked a philosophy, not a tool.
Four Labs, Four Different Races
The frontier-lab conversation has been miscast as a single race with four runners. It is not. It is four different races with four different finish lines.
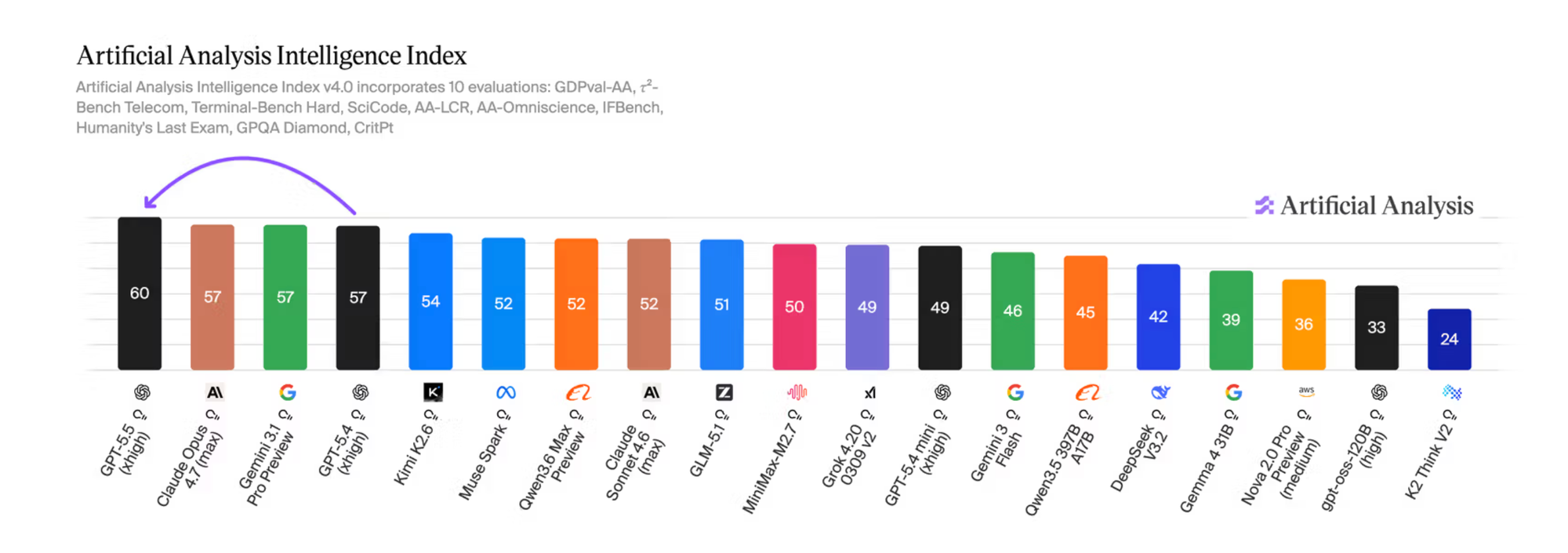
➡️ Sam Altman's team at OpenAI just reclaimed state-of-the-art on 14 benchmarks and is optimizing for agentic computer work at premium pricing, with the super app as the ultimate destination.
➡️ Dario Amodei's team at Anthropic leads on 4 benchmarks, including SWE-Bench Pro (64.3%) and Humanity's Last Exam without tools, and is optimizing for alignment-constrained enterprise with selective gating as a safety stance.
➡️ Demis Hassabis' team at Google DeepMind leads on 2 benchmarks and is weaving Gemini into Google Workspace, Cloud, and Android, where distribution matters more than raw capability.
➡️ Elon Musk's team at xAI is shipping Grok inside X with the most permissive safety posture of the four and is racing on real-time data access as a structural advantage.
For the first time in eighteen months, none of these companies are trying to be the same company. Anthropic is building responsible enterprise AI. OpenAI is building the computer for the AI era. Google is building the productivity stack. xAI is building the real-time, unfiltered frontier.
For me. that divergence is the single biggest signal this week. It means the era of picking one AI vendor and standardizing on it is already over. The companies that win in 2026 will run a multi-model stack, and the stack itself will become core infrastructure.
Reading Between the Lines
We're reaching a really important inflection point on the exponential curve of AI. The second half of 2026 will be dominated by recursive self-improving (RSI) models - that's when the AI builds the AI. This is in large part what's been happening over the past six months, but as we go up the exponential curve, this will accelerate. We tell every board we talk to, this is not about putting AI into your business. You must put your business into AI. We need to really read between the lines and understand what this means for you and your company.
1️⃣ The harness is the new moat. When frontier models converge in raw capability, competitive advantage moves up the stack to the scaffolding around them: orchestration systems, multi-agent frameworks, context management, evaluation harnesses. The models are now reliable enough that the limiting factor is the harness, not the intelligence. Companies that invest in harness infrastructure in 2026 will have compounding productivity advantages through 2027. Companies that rely on out-of-the-box chat interfaces will look like the companies just getting a website when everyone already has one.
2️⃣ Security economics just flipped in both directions. OpenAI's own release notes position GPT-5.5 as capable of identifying and patching advanced security vulnerabilities. CyberGym at 81.8%. Capture-the-Flags internal benchmark at 88.1%. Continuous, full-codebase security review just dropped to near-zero marginal cost. Which means your adversaries have the same tool on the same day. The first company to run GPT-5.5 across their codebase can be ahead of their competition. The last company to do it could be vulnerable to attacks. The new asymmetry is not offense vs. defense, it is speed of adoption vs. speed of attack.
3️⃣ The procurement cycle just collapsed. Enterprise software procurement runs six to eighteen months. Frontier model release cadence is now seven weeks. These two numbers cannot coexist. Either enterprises learn to evaluate, adopt, and deprecate models inside a single quarter, or they standardize on year-old models while competitors run frontier. Most procurement teams are not built for this. Most CIOs have not yet noticed. Most boards have not yet asked.
4️⃣ Labor compression is more subtle than "AI replaces jobs." A twenty-hour engineering task compressed into a twenty-minute model run does not eliminate the senior engineer. It eliminates the junior engineers who used to do the first ten hours of that work. The top of the talent pyramid is safer than it has ever been (for now). The bottom is structurally at risk. Every company building a 2026 headcount plan on 2025 assumptions is planning for a world that no longer exists. The right question is not "how many engineers do I need?" It is "how many orchestrators, reviewers, and senior judgment-layer operators do I need, and where does the entry-level pipeline get rebuilt?"
5️⃣ Governance debt now compounds at model cadence, not board cadence. Every frontier model release means new capabilities, new risks, and new policies required. Boards that meet quarterly are trying to govern technology that ships weekly. The EU AI Act enters force in August 2026 with penalties up to 7% of global revenue, and it was designed around 2023-era models. Enforcement will be retroactive and uneven. The companies that treat AI governance as a continuous function rather than an annual agenda item will absorb regulatory shocks. The others will learn in public.
6️⃣ The model-cadence gap becomes a talent-retention crisis. Your best engineers know which model shipped this week. They are already on it. If your internal tooling is two models behind, they feel it every day. Does this put you at risk with your top talent? Will they end up leaving because your company is falling behind? I believe "inability to use current-generation tools at work" will become a bigger factor that many want to admit.
The Acceleration Question
Jakub Pachocki, OpenAI's chief scientist, stated on the press call, "We see pretty significant improvements in the short term, extremely significant improvements in the medium term. In fact, I would say, I think the last two years have been surprisingly slow."
If this is what "slow" looks like, no one is prepared for when AI acceleration goes up a gear.
Pachocki said this after OpenAI explained that Codex wrote the heuristic algorithms that made GPT-5.5's serving 20% faster on Nvidia's GB200 and GB300 systems. In OpenAI's own words, "the model helped improve the infrastructure that serves it." Brockman confirmed the team used 5.5 and Codex throughout 5.5's own development. Pachocki also said separately: "We actually still have headroom to train significantly smarter models than this."
This is not yet the recursive self-improvement scenario that AI researchers have debated for twenty years. True recursive self-improvement would mean a model meaningfully contributing to the training run of its successor, not just to its serving stack. We are not there. Yet.
But we are now in a regime where:
- Model cadence is seven to twelve weeks, not twelve months.
- Each generation is materially speeding up the infrastructure that trains and serves the next.
- Per-token inference costs are halving every two months per Epoch AI, while training compute grows roughly 5x annually.
- A twenty-hour human coding task compresses into a twenty-minute model run in narrow domains.
- The chief scientist of the leading AI lab publicly describes the last two years as "surprisingly slow."
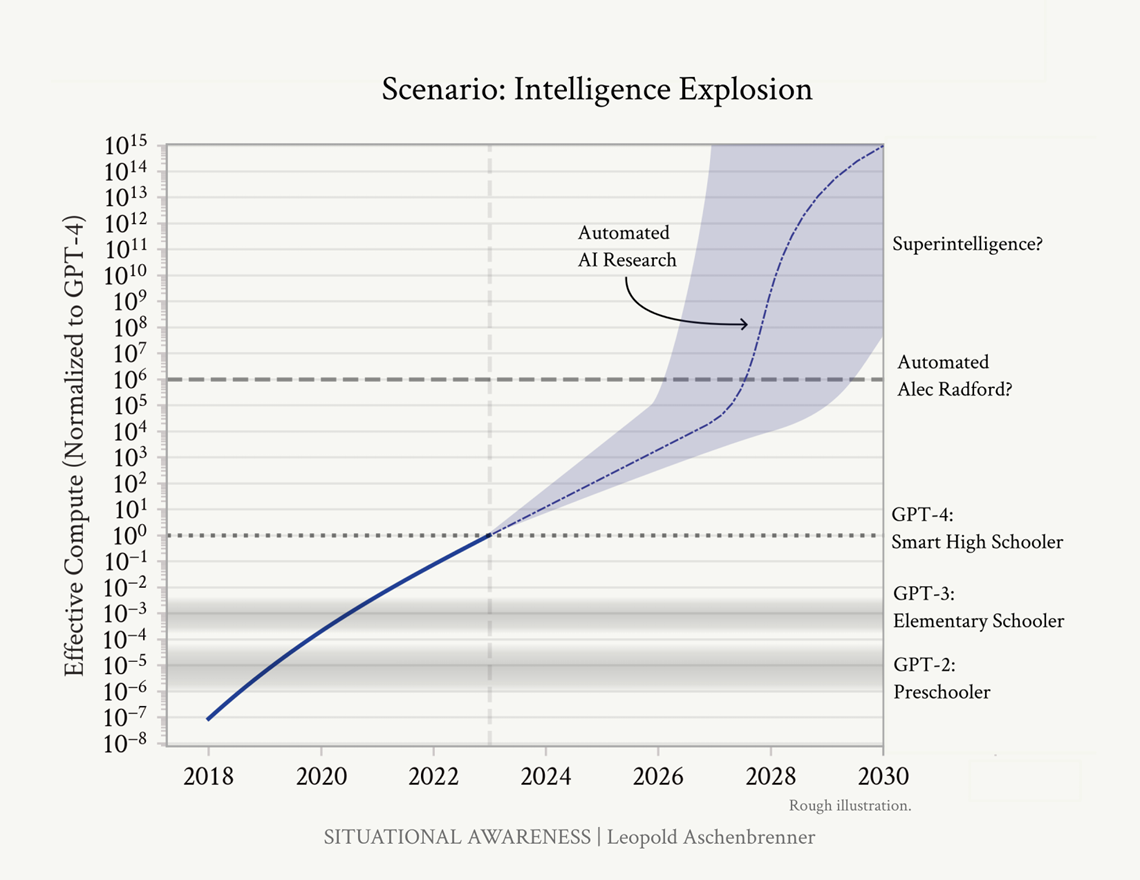
The curve has not gone vertical just yet, but it has steepened significantly. The back half of 2026 will likely bring Claude 5 from Anthropic, Gemini 4 from Google, GPT-6 from OpenAI, and Grok 5 from xAI. It is plausible that at least one will include model-assisted training-data curation, model-assisted reward modeling, or model-assisted architecture search at scale. That is the moment we start calling it acceleration in the formal sense.
Not yet. Soon enough that every operating plan should assume it.
Three Things to Do Before Your Next Board or Leadership Meeting
These are harder than the typical ask. That is the point.
✅ Name a single owner for your AI harness this week. Not a committee. Not a task force. Not a chief AI officer with a fifteen-slide mandate. One person, senior enough to reallocate capital, technical enough to actually use the tools, reporting to the CIO or CEO. Their remit is the harness itself: orchestration, multi-agent design, context management, evaluation, permissioning, and the weekly discipline of testing every frontier release against your real workflows. The models will converge. The harness is where advantage compounds. If you do not have this role named by your next board meeting, your AI strategy is insufficient.
✅ Run GPT-5.5 against your production codebase this week. Not a vendor pilot. An internal exercise. Run the same task against Opus 4.7 and compare. OpenAI's own release notes describe GPT-5.5 as capable of identifying and patching advanced security vulnerabilities. CyberGym at 81.8%. Your adversaries have access to the same tool on the same day. The cost of running this is measured in hundreds of dollars. The cost of not running it shows up in your next breach disclosure, and your D&O carrier will ask why you did not.
✅ Put your CFO, CIO, and CHRO in one room and write the 2026 absorption plan. Dozens of more frontier model releases are coming this year. How many does your current plan assume? Your new plan has to cover workflow redesign, role redefinition (including the junior tier that a twenty-hour-to-twenty-minute compression is quietly eliminating), procurement cycle compression, training curriculum, and governance escalation. If it does not assume a release cadence shorter than your planning cycle, you're not addressing the current reality of AI advances. If your CHRO is not in the room, you will be rebuilding the plan in the near future, after your entry-level pipeline has collapsed and your best engineers have left for a company that ships faster.
Now is the time to lead.
For more, sign up for Alpha BoardBrief https://boardbrief.alpha.ac/




